


Oracle disk IO latency on EC2
A colleague pointed me to this blog post , in which one attendees at a cloud computing panel described disk IO in the cloud (presumably AWS) as "punishingly slow".
We use EC2 for testing purposes here in the Spotlight on Oracle team, and generally we’ve been pretty happy – at least with throughput. Latency is a bit of a mixed bag however. Here’s a typical db file sequential read histogram from one of our bigger EC2 instances (from Spotlight on Oracle):
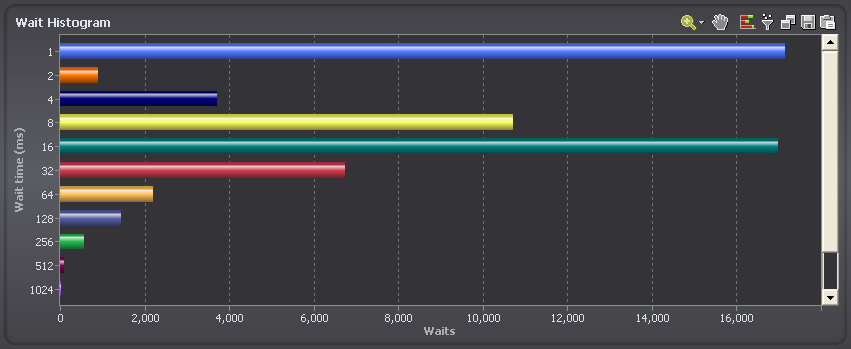
We do a fair bit of benchmark related workloads, so of course we often overload the disks. However, the two peaks in the above chart are interesting. The 1 ms peak is clearly caching of some form – disks simply cannot return blocks of data in 1ms for random reads given rotational latency, etc. The 1 ms disk reads are probably coming from a non-volatile cache incorporated with the virtual disks (and yes, Oracle was configured with filesystemio_options set to ‘setall’, so filesystem caching was not in effect)
The 16ms peak is poor if that represents the actual physical service time of the disk; but it might be due to overloading the disks and creating some queuing. Let’s try and find out.
When you create an EC2 instance, by default your storage is “ephemeral” – non permanent. It’s more sensible therefore to create datafiles on Elastic Block Storage (EBS) devices that will not evaporate should your instance crash. I was interested in the relative performance of both. You probably never want to store tables on ephemeral storage, but maybe they could be used for temporary or index tablespaces.
I created two tables, one on a EBS backed tablespace and one on ephemeral storage. The table had a 7K row length, so each row was in a block of its own. I then retrieved blocks from the table in sequential order after – of course – flushing the buffer cache and making sure filesystemio_options where set to “setall”. The primary key indexes were on separate tablespaces, so we’re only seeing the IO from the table reads.
These first results were very good (this is from V$FILE_HISTOGRAM):
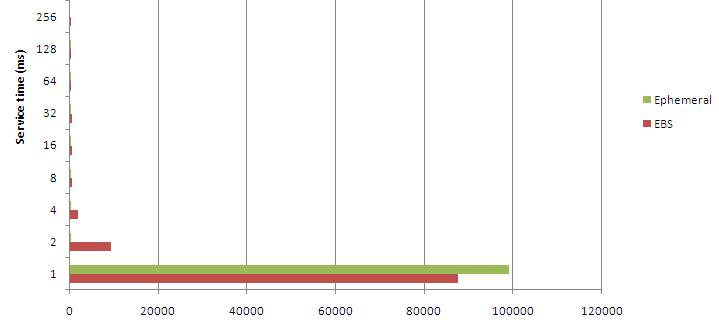
These results show that Ephemeral is a bit faster than EBS, but that EBS still seems VERY fast. Too good to be true in fact: must be some caching going on in the EBS storage layer.
I restarted the instance (and database of course) and waited a few hours. Hoping that whatever cache exists had been purged. However, the results were not much different. Perhaps my 8K block reads were piggy-backing on a larger block size in Amazon storage? So the first time I read an 8K block it takes 4-8ms, but when I then read a "nearby" block, it's already cached?
So next, I tried performing random reads on a really massive table to try and prevent this sort of caching. I used SQL trace to capture all the db file sequential read times. The following perl snippet was used to collect the distribution of IO times (77203 is the obj# of my test table):

Now we see something that looks like it might reflect more accurately the non-cached EBS response time:
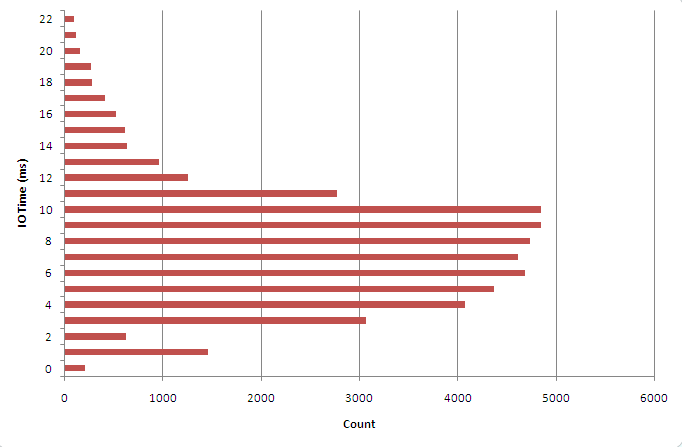
These times aren’t that great, but aren’t totally outside the range of what we’re used to in JBOD (Just A Bunch Of Disks).
So based on this little bit of research, here’s my current take on EC2 IO latency:
- The underlying disk system implements some form of caching: as a result disk reads often appear to be super-fast if they are pick up data in the storage cache. For a typical database, this will make some proportion of single block reads appear to complete in 1ms range.
- When the cache is bypassed, latencies of between 4-10 ms can be expected.
- Ephemeral storage appears to be somewhat faster that EBS. You'd be nuts to put any data you wanted to keep on ephemeral storage, but maybe we could consider using it for temporary tablespaces.
I did a little bit of work on throughput while writing Oracle Performance Survival Guide. Here's a chart that shows an attempt to push up read throughput on an EBS based tablespace:
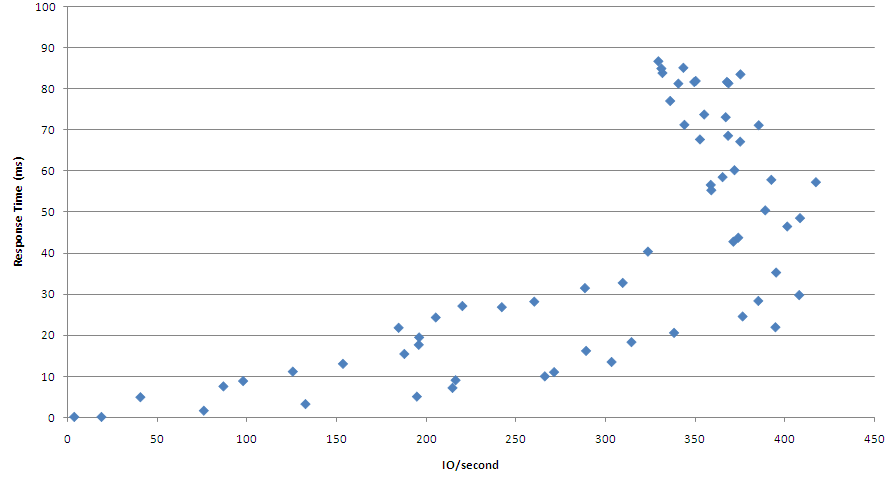
I really need to spend some more time benchmarking throughput, but based on this simple test, it seems like you can get a couple of hundred IOPS out of an EBS filesystem before latency starts to run away.
 Guy Harrison
Guy Harrison
Reader Comments (1)
You can achieve radically better overall IOPS by using ASM or an LVM to stripe across multiple EBS volumes. This is Amazon's intended architecture for enterprise class deployments like Oracle.
Regards,
Jeremiah