In this post I'm going to report on some performance comparisons I've recently conducted on using SSD flash storage for datafiles vs. using the new Oracle 11GR2 database flash cache.
It sometimes seems like I’ve been waiting for the the end of the spinning magnetic disk all my professional life. The technology is so ancient, so clearly limited and (argh) mechanical. So the fact that Solid State Disk (SSD) is becoming more an more practical as a database storage medium - and directly supported by Oracle in 11GR2 - is very exciting.
Using SSD as part of database storage can certainly yield big results, but it's important to understand the performance characteristics of flash SSD and make sure we don't use it inappropriately.
SSD comes in two flavours:
- Flash based SSD uses the familiar flash technology that underlies the ubiquitous USB drives that have replaced floppy disks for small portable data storage. Flash RAM is cheap, provides permanent storage without battery backup and so has low power consumption.
- DDR RAM based SSD uses memory modules that are not particularly different in nature from those that provide core memory for the server. This RAM is backed by non-volatile storage (disk or flash RAM) and internal batteries. In the event of a power failure, the batteries provide enough power to write the RAM memory to the non-volatile storage.
DDR SSD is too expensive (in terms of $$/GB) to be very useful to we database professionals today. But Flash based disk is becoming an increasingly viable alternative to magnetic disk.
Read, write and erase operations
Flash disk storage is organized into pages – typically 4K – and blocks – typically 256K. For read operations, the flash disk can return data very quickly from individual pages. Writing to a page is slower – maybe 10 times slower. However, it is only possible to write a page of data if there is an empty page in the block. If we need to write to a full block, it must first be erased. The Wikipedia entry on SSD gives the following figures for seek, write and erase times:
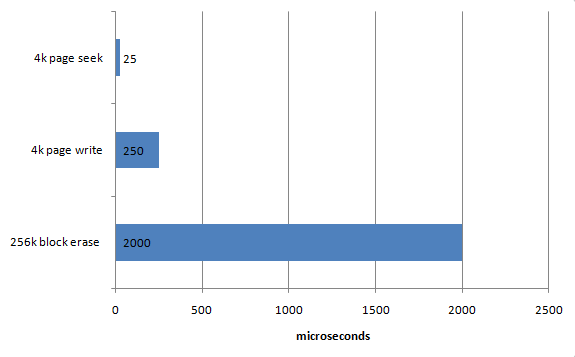
As a flash SSD fills with data, the percentage of simple block level writes that require an erase increases, and the write performance of the flash SSD degrades.
The TRIM API function
High end flash SSD support an API call TRIM, which allows the OS to proactively erase full blocks so that writes can complete with only a page-level IO. Most high end drives also support wear-leveling algorithms that move hot-pages around the device to avoid the risk of block level failures. Flash drives can only support a limited number of erase operations before a block becomes unreliable, but this is minimized providing the disk automatically moves hot pages around in physical storage.
MLC vs SLC
Cheap flash drives generally use Multi-Level-Cell (MLC) technology in which each cell can store two bits of data rather than SLC which can only store one bit. The effect of MLC is to increase density at the expense of performance, particularly write performance. MLC is also less reliable in terms of data loss. If you’re concerned about write performance – and you probably should be – then you should avoid MLC.
In general, if you want a high performance flash SSD - and why get one if it's not high performance - you should go for a SLC based flash SSD that supports the TRIM API and has good wear leveling capabilities. For my testing, I used an Intel X-25 E 32GB drive. It cost about $600 Australian (about $534 US dollars).
The problem with read/write speed disparities
Given that most databases do many more reads than writes, do we need to worry about the disparity between seek times and write times for flash SSD? The answer is definitely YES. For an Oracle database, a big mismatch between the ability to read from a device and the ability to write to the device can be particularly harmful when performing transactional activity through the buffer cache.
The issue relates to the caching of data within the buffer cache. If it’s very much easier to put blocks into the buffer cache than to write them out, then there’s a good chance that the buffer cache will fill up with dirty (unmodified) blocks and that free buffer waits will result. The figure below illustrates how free buffer waits can occur:
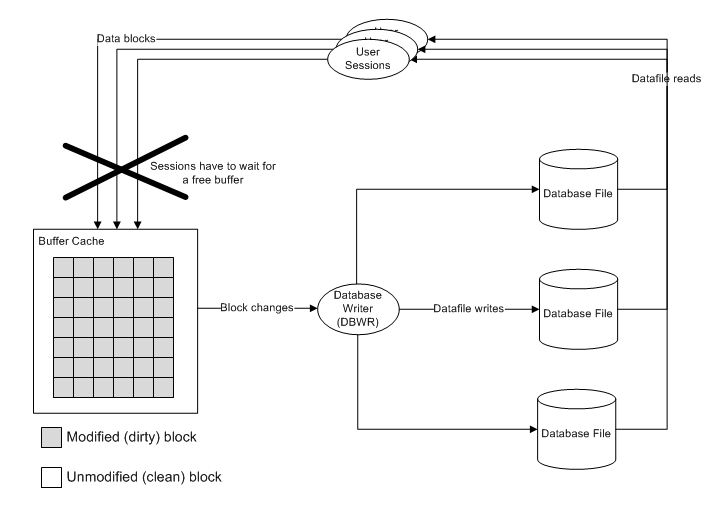
(This illustration from Oracle Performance Survival Guide).
If you're using cheap flash drives, then the write speed is going to be much slower than the read speed and consequently you could end up with free buffer waits becoming your limited factor during high transactional activity.
Enter the Oracle Database Flash Cache
Oracle's database flash cache provides an alternative way of exploiting flash SSD. Instead of putting the entire datafile on flash, we use flash as a secondary cache. The flash cache can be massive and can speed up reads for frequently accessed blocks. But if the flash drive is busy, Oracle will simply decline to write to the cache. That way we can get some of the advantage of flash for read optimization without having to pay the write penalty.
I outlined the flash cache algorithms in this previous post, and here's the diagram I used there to outline the lifecycle of a block when the database flash cache is enabled:
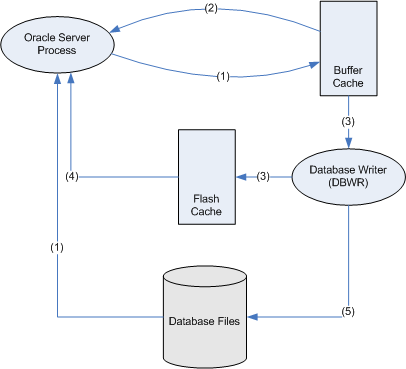
The important part of this architecture is that the DBWR will only write the block to the flash cache if it is not overloaded. If the DBWR gets busy, then the flash cache write can be omitted and while this will reduce the efficiency of the cache, it prevents the buffer cache from filling up with modified blocks - so free buffer waits should not result.
Flash disk read performance
Let's see how this pans out in practice. Below we see the relative performance for 500,000 random indexed reads against:
- A table on magnetic disk with no flash cache
- A table on magnetic disk with flash caching
- A table stored directly on flash disk
The magnetic disk was a Seagate 7200.7 80GB Barracuda drive, while the Solid State Disk drive was an Intel X-25 E 32GB drive which is a pretty high end SLC drive. In both cases, the tablespaces were created on raw partitions to avoid filesystem caching and the redo logs and other tablespaces were on a seperate drive. The database was restarted prior to each test.
Here's the read performance:
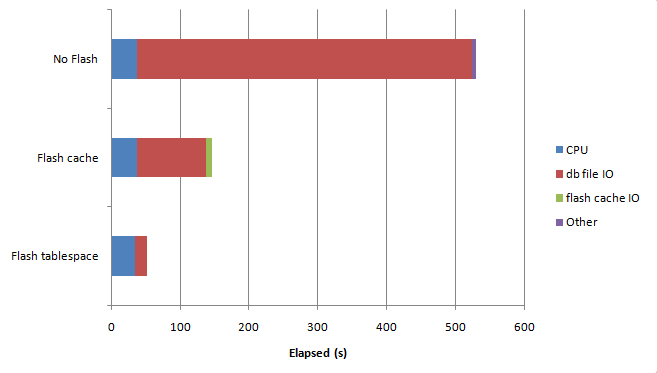
As you'd expect, storing the table directly on flash is fastest, since there are only read I/Os, and every read I/O is from the much faster flash SSD. Note that the flash cache gives us a lot of advantages as well - the number of database file IOs is reduced, and the reads from the flash cache are very fast indeed.
Update performance
Next I measured the performance of primary key based UPDATEs. The performance for such an UPDATE is a mix of read time - get the block into cache - and DBWR performance. If the DBWR can't write the modified blocks out fast enough then free buffer waits and/or write complete waits will occur.
What I expected was that the flash tablespace test would show a lot of free buffer waits, since in theory flash writes are so much slower than flash reads. I thought that using the flash cache would avoid that issue, and provide the best performance. However, the results surprised me:
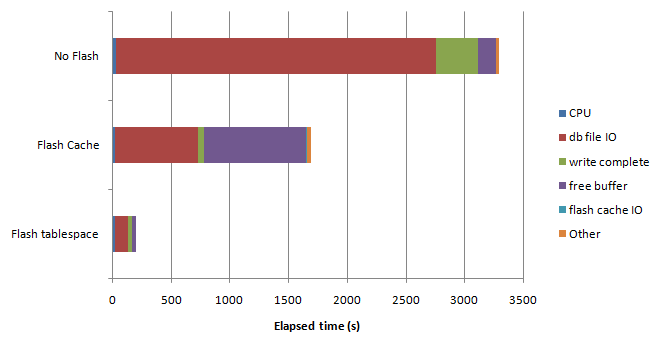
I repeated the above tests about a dozen times with a variety of workloads, but the results were pretty similar in every case. While using the flash cache is better than no flash at all, it's still better to put the table directly on flash storage. The X-25 E was simply able to sustain a write rate much higher than I had expected - about 2,000 writes/sec. Intel claim - and now I believe - that they have sophisticated algorithms that avoid the write penalty usually associated with the flash SSD storage medium.
Note that it's actually the Flash Cache configuration that generates the most free buffer waits. The flash cache allows Oracle to achieve much higher logical read rates but - since the writes still go to the relatively slower spinning magnetic disk - the buffer cache often fills with dirty blocks.
It may be that over time the performance of the X-25 will reduce when all the blocks have been written to at least once Erase operations become more prevalent. However, if the TRIM API is working properly then this degradation should in theory be avoided. Note that TRIM support is not universal - not all SSDs and older versions of Windows may not support it.
Write complete waits: flash cache
In previous postings I noted that the DBWR will skip writing to the flash cache when busy, which should prevent flash cache activity being a direct cause of buffer busy waits. However, I noticed under some workloads that I would get a large number of "write complete waits: flash cache". For instance, the output below shows about 74% of elapsed time in this wait:
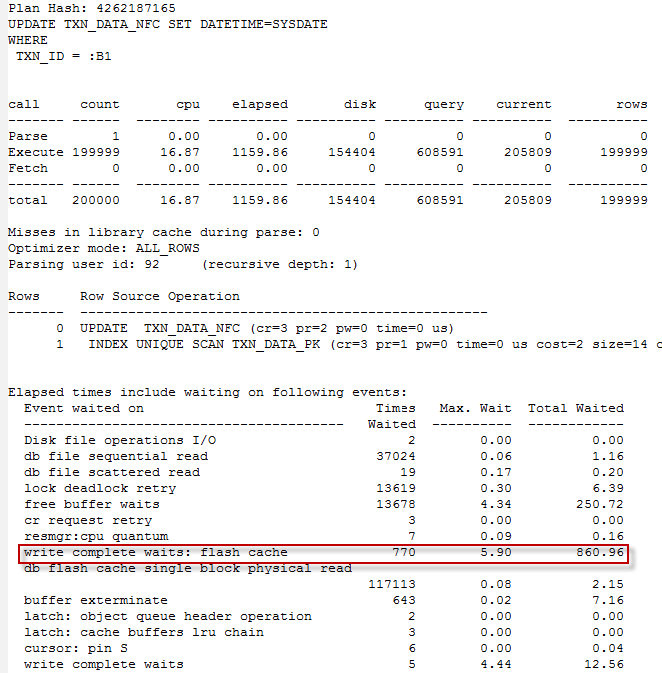
Write complete waits occur when a session wants to modify a block, but the DBWR is in the process of writing it out to the datafile. The flash cache equivalent occurs for the same reason, but instead of writing it to the datafile, the DBWR is writing it to the flash cache. This phenomenon can occur when individual blocks are being modified at very high rates; in this scenario, the chance that the block will be modified before the DBWR writes it out can be substantial.
Conclusion
I'm very impressed with the performance of the X-25 E flash SSD drive. If it can maintain it's high write throughput over time, then it offers a significant increase in throughput over traditional spinning disk or over the new 11GR2 database flash cache. However, a few words of warning:
- I did not stress test the disk over a long period of time. Some flash drives exhibit more write latency as they wear in. In theory, the TRIM functionality of the Intel X-25 E should avoid that, but I did not verify it in these tests.
- Flash drives can be an unreliable form of storage over long periods of time. Any disk can fail of course, but if you run a flash disk hot it will likely fail before a magnetic disk (though it will do more work during that period).
- In my tests, my table was small enough to fit on the flash storage. Had it not, then using the database flash cache would have allowed me to get some benefits from the flash drive without having to buy enough storage to fit the whole database on the SSD.
I'm now even more enthusiastic about the use of flash drives. Providing you buy a high-performance drive (think SLC & TRIM) then you could consider placing entire tablespaces or database on these drives. If you can't afford top end flash drives for all your data, then the 11GR2 database flash cache can give you a pretty substantial performance boost.



 Guy Harrison
Guy Harrison