


Performant Oracle programming: perl
In the last installment, we looked at the fundamentals of efficient Oracle programming with C#. In particular, we saw how to use bind variables and how to perform array processing. Now lets take a look at perl.
I have a strong affection for perl: I started using perl somewhere in the early nineties and did some simple hacking to allow the Oracle interface of the day - oraperl - to use stored procedures. My very first true performance monitoring tools were all written using perl. Perl has always had good support for Oracle and it's possible to write very efficient and powerful Oracle database utilities in perl.
You can get the perl program that implements the examples in this posting here.
Thanks for all the perl!
Anyone who uses perl with Oracle today owes a debt of thanks to the many people who have maintained the Oracle perl interface (DBD::Oracle) over the years.
Kevin Stock created the original perl 4 "oraperl" modules, which Tim Bunce used to create the modern DBD::Oracle. Tim maintained it for many years, but handed it over to John Scoles of the Pythian group in 2006. Pythian are now sponsoring the ongoing maintenance of DBD::Oracle and they do this without any particular expectation of financial reward. It demonstrates what great guys and outstanding members of the Oracle community they are, and those of us using DBD::Oracle owe them a debt of gratitude. The Pythian hosted home page for DBD::Oracle is here.
Bind variables
As with most languages, it's easier in perl to use literals than to use bind variables. So for instance, in the following snippet we issue the same SQL statement in a loop, but because we are inserting the literal value of the variable "$x_value" into the SQL on line 236, Oracle will consider every SQL to be a unique statement.
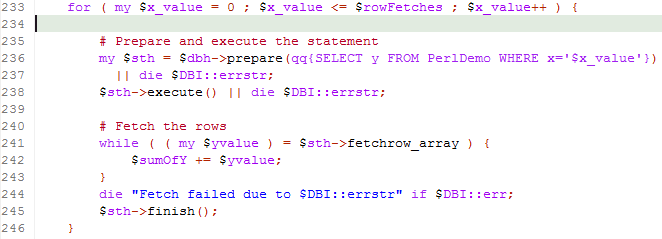
To use bind variables, it's simply required that you insert a placeholder in your SQL text - either a "?" or numbered parameters like ":1", and then assign them values with the bind_param call (see line 184 below). Note that we prepare the statement only once (on line 179) even though we bind and execute it many times.

Using bind variables results in significant performance gains, both because of the reduction in parse time CPU and because of the reduced contention for library cache mutexes. When I ran the script I was the only user on the database so mutex contention was not an issue. Even so, the reduction in parse time resulted in an almost a 75% reduction in execution time:

Array Fetch
Array fetch is handled automatically by DBD::Oracle. The RowCacheSize property of the database handle sets the size of the fetch array, which by default is set to 500.
Perl supports a range of fetch methods: fetchrow_array, fetchrow_arrayref, fetchrow_hashref and fetchall_arrayref. DBD::Oracle uses array processing regardless of the DBI method you use to fetch your rows.
In the following example, we set the array fetch size, then process each row one at a time. DBD::Oracle fetches rows in batches behind the scenes.
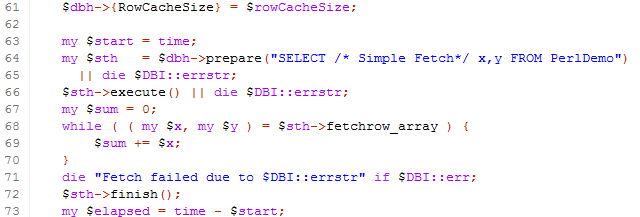
We set the size of the array on line 61. You don't really need to do this unless you think that 500 is an inappropriate array size - perhaps if the row size is very small or very large.
A casual look at the DBI APIs might suggest that you need to use the fetchall_arrayref method to exploit array processing. For instance, in the following perl code, the contents of the PERLDEMO table are loaded into a array of rows in a single call.

Fetching the data in this way actually doesn't change the size of the array requests to Oracle: all it achieves is to load all the rows into local memory. This is usually not a good idea for massive tables, since you may get a memory allocation error or starve other programs - including Oracle - for memory. Even if you don't cause a memory shortage, the overhead of allocating the memory will usually result in slower processing than if you process the rows using fetchrow_array or one of the other row-at-a-time fetch calls.
Array Insert
As with a lot of languages, it's easy to fetch in arrays in perl, but slightly harder to insert with arrays. The "natural" way of inserting rows is to bind each row into the INSERT statement and execute. Here's that simple technique, which does not exploit the array interface:

The value for the row to be inserted is bound in lines 148-149, then inserted in line 150. Each row is inserted in a separate call, and so every row requires a network round trip to the database and a unique interaction with the oracle server code.
It's only a little bit more complex to bind an array:

We bind the arrays using the bind_param_array method on lines 133 and 134. The execute_array method (line 136) activates the array insert. The size of the array can be adjusted by setting the ora_array_chunk_size property (line 132).
As in all languages, it's a very significant improvement to use array insert. We see below that using the array methods reduced elapsed time by over 80%:

Conclusion
Perl supports a very rich and mature interface to Oracle and it's certainly possible to write high-performance perl programs that interact with Oracle.
Although it's usually not necessary to explicitly code array fetch, you do need to explicitly code bind variables and array inserts and you should generally do so if you wish your perl script to interact efficiently with Oracle.
There's lots of other performance features of the DBD::Oracle driver that I haven't covered in this basic introduction. You can read up on all the capabilities of the driver in its documentation page on CPAN.
 Guy Harrison
Guy Harrison
Reader Comments (4)
I just wanted to give you a quick thanks for this post. I am new to Oracle, and this information helped me to reduce run time from 1+ hours to 5 minutes!
Thanks again!
I am looking to use perl to unload data from Oracle. Here you describe its use of Array Fetch but I have seen this site:
http://www.dba-oracle.com/t_dbi_dbd_features.htm
Were it says this is not implemented as a single interaction with the database but rather a loop of multiple interactions. Plaes can you confirm if this is the case.
Thanks
Daniel
It looks like he didn't set the ora_array_chunk_size in his example which may explain why he's not seeing array inserts. I did perform the test in the post and it did show the speed up reported. You could always run it yourself and do a trace to see what was happening. I don't have the test bed to do that right now.
Hi,
Nice article , good information , it is usefull to m any people.
What are the competitors to Oracle Exadata?
Thanks,
Divya,
Oracle developer