


Pivot performance in 11g
"Pivoting" a result set - mapping values in a particular row to columns - is a commonplace activity when analyzing data in spreadsheets, but has always been a bit awkward in SQL. The PIVOT operator - introduced in Oracle 11g - makes it a somewhat easier and - as we'll see - more efficient.
Prior to PIVOT, we would typically use CASE or DECODE statements to create columns that contained data only if the pivot column had the appropriate value. For instance, to produce a report of product sales by year, with each year shown as a separate column, we might use a query like this:
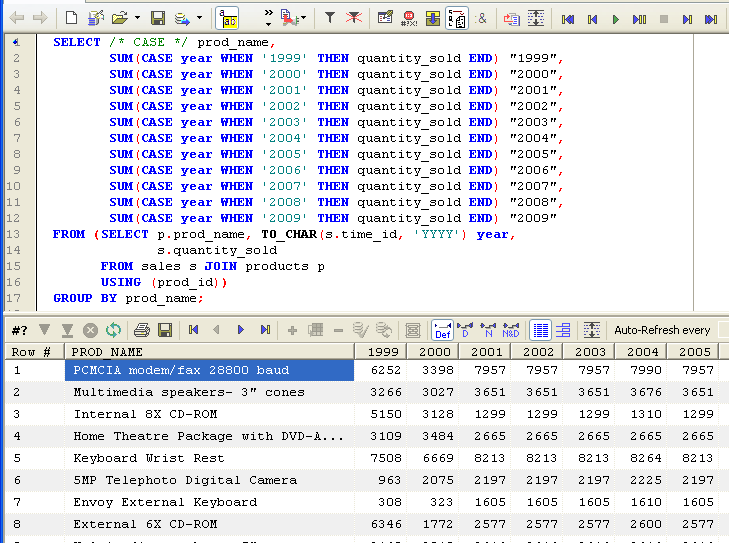
You can use either CASE or DECODE to map specific values to specific columns. CASE is more modern and possibly a better general purpose tool, but DECODE works fine.
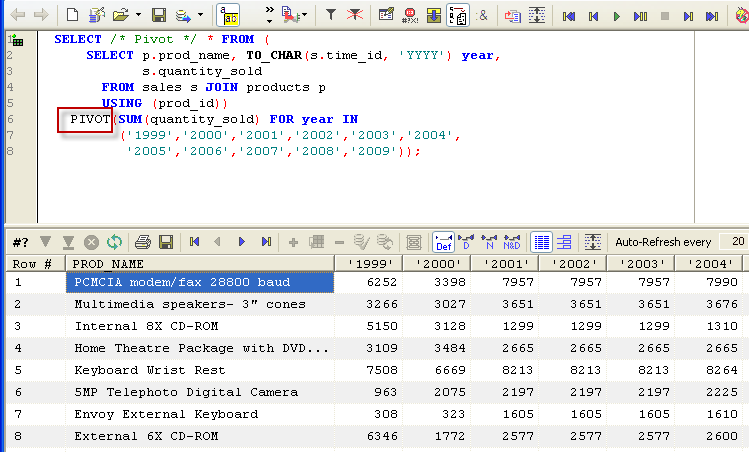
PIVOT provides a more succinct syntax, though we still need to specify the exact column values we want (for instance, it would be nice below to be able to somehow specify "all years" instead of having to itemize the specific years to be mapped to columns):
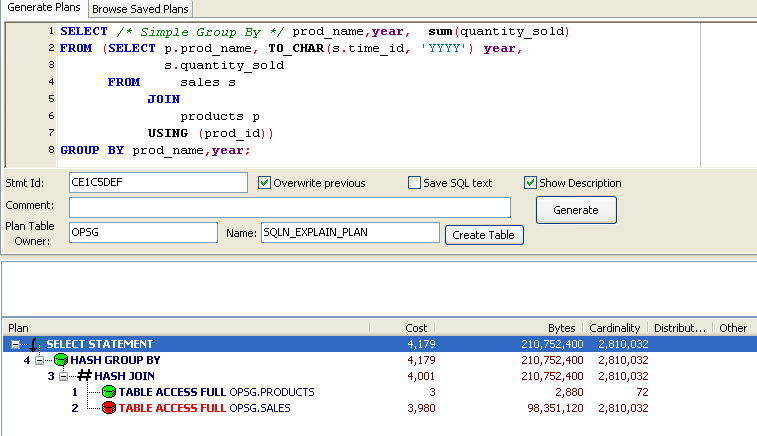
So new syntax is all very well, but does it make a difference to performance? Comparison of the execution plans shows very little difference between the two approaches. Below we see the CASE based plan on the left and the PIVOT plan on the right. Both plans have identical cost and - other than for a PIVOT option in the GROUP BY clause - exactly the same plan:

It's very,very common for the cost calculations in the optimizer to lag behind new operations, so we don't want to take the cost estimate as gospel. It's clear that Oracle doesn't have a clue as to the overhead of actually performing the pivot, since a simple GROUP BY with no pivot operation generates exactly the same cost:
However, generating and analyzing a SQL trace with the CASE, DECODE and PIVOT alternatives showed that PIVOT was a lot less CPU intensive. The following is from Spotlight on Oracle but of course you could use tkprof to get most of the relevant data from the trace file:
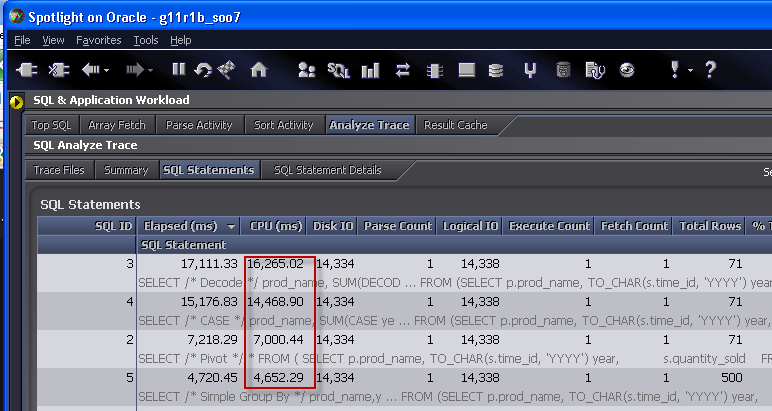
Each approach - CASE, DECODE, PIVOT - involved about the same amount of physical and logical IO, but the PIVOT used much less CPU - less than half. Since I love charts, here's the same data in a chart:
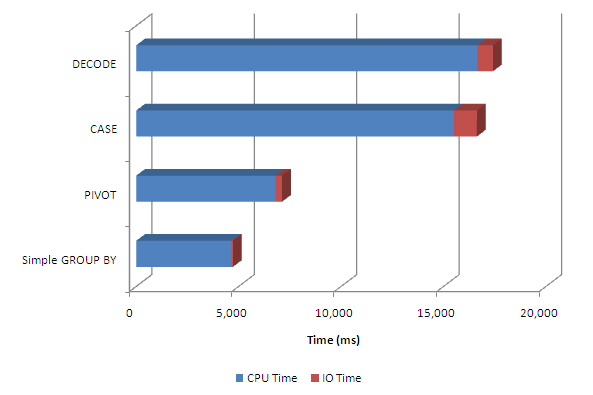
PIVOT is a bit more expensive than just spitting out the raw data (and maybe pivoting in Excel), but it's way cheaper than the CASE or DECODE based alternatives.
When we use the CASE approach, we force Oracle to perform multiple CASE statement expressions on every row before the GROUPING. These evaluations are very CPU intensive and it's easy to imagine that the PIVOT algorithm could be more efficient. However, it's interesting to see that - as yet - the optimizer is unable to factor in the cost of either the CASE or the PIVOT.
In summary, PIVOT seems to be pretty efficient, and certainly much less CPU intensive than the pre-11g CASE or DECODE alternatives.
 Guy Harrison
Guy Harrison
Reader Comments