


Optimizing GROUP and ORDER BY
Starting with Oracle 10.2, you may notice a significant degradation in relative performance when you combine a GROUP BY with an ORDER BY on the same columns.
Oracle introduced a hash-based GROUP BY in 10.2. Previously, a GROUP BY operation involved sorting the data on the relevent columns, then accumulating aggregate results. The hash GROUP BY method creates the aggregates without sorting, and is almost always faster than sort-based GROUP BY. Unfortunately, when you include an ORDER BY clause on the same columns as those in the GROUP BY Oracle reverts to the older sort-based GROUP BY with a corresponding drop in performance. However, you can reword your SQL to take advantage of the hash-based GROUP BY while still getting your data in the desired order.
For example, consider this simple statement:

Prior to 10.2, the statement would be executed using a SORT GROUP BY operation:

From 10.2 onwards, we can expect to see the HASH GROUP BY :

As Alex Gorbachev noted, the new GROUP BY can return bad results in early versions (prior to 11.1.0.7 or 10.2.0.4). You can disable by setting the parameter _GBY_HASH_AGGREGATION_ENABLED to FALSE. Below, we use the OPT_PARAM hint to set this for an individual SQL; you could also use ALTER SESSION or ALTER SYSTEM to change the parameter at the session or instance level:
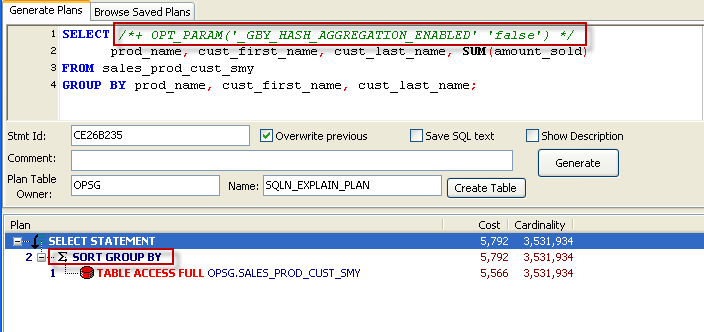
The other thing to remember is that you can't rely on GROUP BY returning rows in order; prior to 10.2 GROUP BY would usually return the rows in the GROUP BY order, and some of us may have consequently not bothered to add an ORDER BY clause. On upgrading to 10.2, you might have been surprised to see queries suddenly return data in apparently random order. Tom Kyte talks about this here: as a general rule you should never rely on a side-effect to get rows in a particular order. If you want them in order, you should always specify the ORDER BY clause.
Generally speaking, the new hash GROUP BY is much more efficient than the older sort method. Below we see the relative performance for the two GROUP BY algorithms when grouping a sample table of 2.5 million rows into about 200,000 aggregate rows:
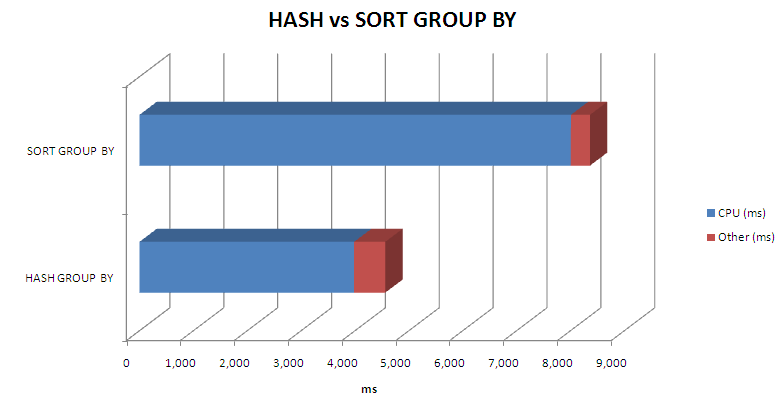
Your results may vary of course, but I've not seen a case where a SORT GROUP BY outperformed a HASH GROUP BY.
Unfortunately, Oracle declines to use the HASH GROUP BY in some of the circumstances in which it might be useful. It's fairly common to have a GROUP BY and an ORDER BY on the same columns. After all, you usually don't want an aggregate report to be in random order.
When Oracle uses the SORT GROUP BY, the rows are returned in the grouping order as a side effect of the sort. So in the example below, there is just one SORT - it supports both the GROUP BY and ORDER BY (note that i've turned off the HASH GROUP BY using the OPT_PARAM hint):
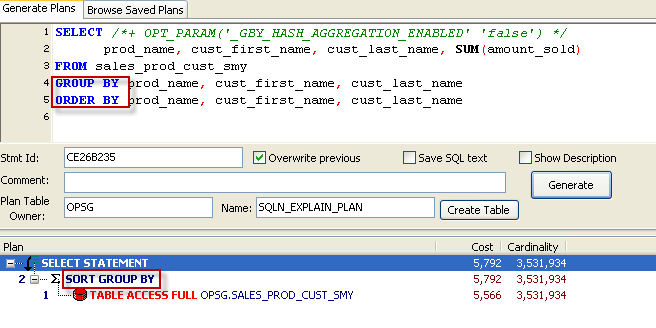
The above plan is what you'd expect to see prior to 10.2 - since the HASH GROUP BY is not available in that release.
However, when we examine the execution plan in 11g or 10.2 we find that Oracle still chooses the SORT GROUP BY:
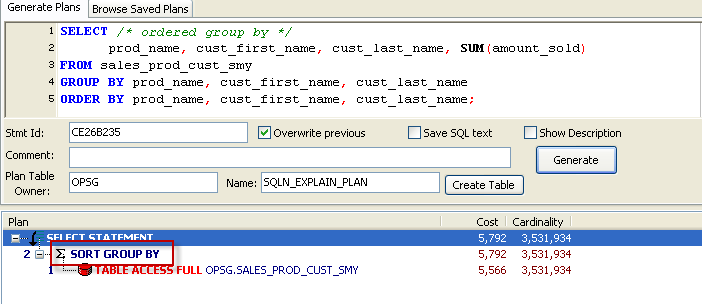
Here's the important point:
When you combine a GROUP BY and an ORDER BY on the same column list, Oracle will not use the HASH GROUP BY option.
Presumably, the optimizer "thinks" that since the SORT GROUP BY allows Oracle to get the rows in sorted order while performing the aggregation, it's best to use SORT GROUP BY when the SQL requests an ORDER BY as well as the GROUP BY. However, this logic is seriously flawed. The inputs to the ORDER BY will normally be far fewer rows than the inputs in to the GROUP BY. In our example above, the GROUP BY processes about 2.5 million rows, while the ORDER BY sorts only about 200,000 rows: it really doesn't make sense to de-optimize the expensive GROUP BY to optimize a relatively cheap ORDER BY.
Is there a way to force Oracle to use the HASH GROUP BY even if we have the ORDER BY? I'm not aware of an optimizer parameter or hint, but I was able to persuade Oracle to use the HASH GROUP BY by putting the GROUP BY in a subquery, the ORDER BY in the outer query, and using the NO_MERGE hint to avoid having the subquery merged into the outer query. Here's my query and execution plan showing that I get a HASH GROUP BY together with SORT ORDER BY:
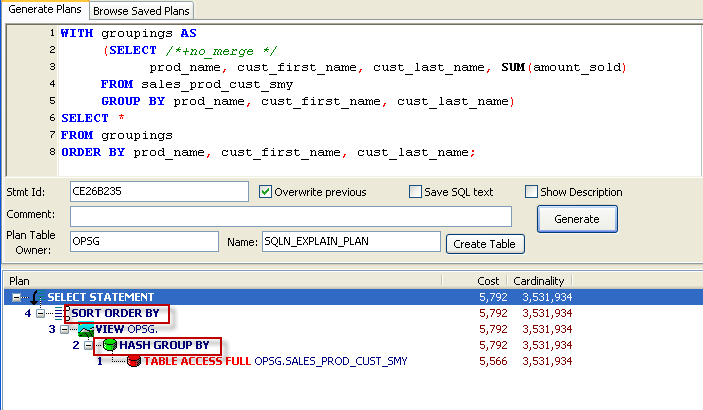
You might think that doing a single SORT GROUP BY is better than doing both a HASH GROUP BY and a SORT ORDER BY. But remember,the SORT ORDER BY only has to sort the grouped rows - about 200,000 in my example - while the GROUP BY has to process the entire contents of the table - about 2.5 million in my sample table. So optimizing the GROUP BY is often more important than avoiding a small second sort.
Here's a comparison of performance between the two approaches:
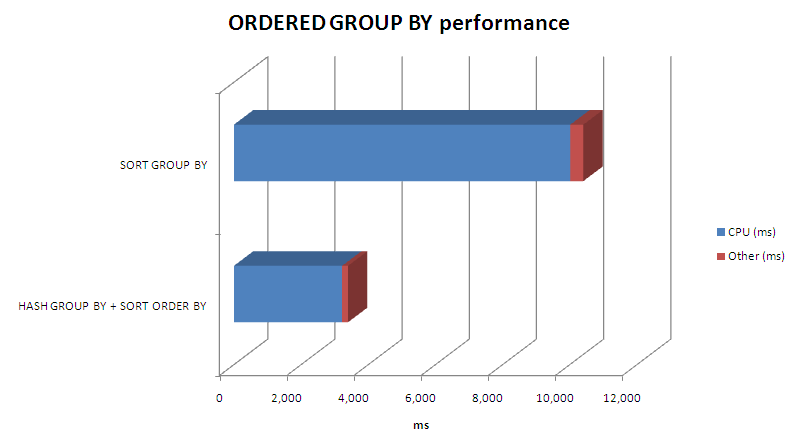
The rewrite reduced elapsed time by about 2/3rds.
Conclusion
When a GROUP BY is associated with an ORDER BY on the same columns, the Oracle optimizer may choose a SORT GROUP BY rather than the usually more efficient HASH GROUP BY. Using the SORT GROUP BY avoids adding a SORT ORDER BY to the plan, but the overall result is usually disappointing.
To get a better result, you can perform the GROUP BY in an in-line view and perform the ORDER BY in the outer query. Use the NO_MERGE hint to prevent the two operations from being combined.
 Guy Harrison
Guy Harrison
Reader Comments (13)
The hints USE_HASH_AGGREGATION & NO_USE_HASH_AGGREGATION can be used to control the hash group by aggregation as well.
Yes, silly me. I overlooked that hint. So in the above examples, the following SQL:
SELECT /*+USE_HASH_AGGREGATION*/
prod_name, cust_first_name, cust_last_name, SUM(amount_sold)
FROM sales_prod_cust_smy
GROUP BY prod_name, cust_first_name, cust_last_name
ORDER BY prod_name, cust_first_name, cust_last_name
Performs a HASH GROUP BY followed by a SORT ORDER BY and provides the same performance as my more convoluted solution :-(.
Unfortunately, the hint does not work in the following scenario:
sqlplus xyz/xyz
SQL*Plus: Release 11.2.0.1.0 Production on Sun Mar 7 18:41:59 2010
Copyright (c) 1982, 2009, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> set line 10000
SQL> set autot on explain
SQL> create table t1(x int, y int);
Table created.
SQL> select x, count(unique y) from t1 group by x;
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 3640378487
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 26 | 3 (34)| 00:00:01 |
| 1 | HASH GROUP BY | | 1 | 26 | 3 (34)| 00:00:01 |
| 2 | VIEW | VM_NWVW_1 | 1 | 26 | 3 (34)| 00:00:01 |
| 3 | HASH GROUP BY | | 1 | 26 | 3 (34)| 00:00:01 |
| 4 | TABLE ACCESS FULL| T1 | 1 | 26 | 2 (0)| 00:00:01 |
----------------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> create table t2 as select * from t1;
Table created.
SQL> insert into t2 select/*+USE_HASH_AGGREGATION*/ x, count(unique y) from t1 group by x;
0 rows created.
Execution Plan
----------------------------------------------------------
Plan hash value: 3946799371
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------
| 0 | INSERT STATEMENT | | 1 | 26 | 3 (34)| 00:00:01 |
| 1 | LOAD TABLE CONVENTIONAL | T2 | | | | |
| 2 | SORT GROUP BY | | 1 | 26 | 3 (34)| 00:00:01 |
| 3 | TABLE ACCESS FULL | T1 | 1 | 26 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
SQL>
Apparently, any DML disables' hash group by', hint or no hint.
VJ
Yes, I observed the same result as V J Kumar: when subquery is used to insert records into another table, Oracle seems to always use sort group by, even hint USE_HASH_AGGREGATION is in place.
Hi,
Settiing the _GBY_HASH_AGGREGATION_ENABLE=true, will it consume more PGA?
Thanks & Regards,
Deepak
I don't expect so - with other hash vs sort operations I've found the hash operation to use less memory. I haven't tested it for hash group by though.
In 9i when Oracle retrived data from an index it kept it sorted. Since upgradeing to 11g I noticed that my queires that didn't contain an order by caluse weren't coming back sorted. Is there any parameter in the database or other work around setting that force a sort?
I'm not aware of any specific changes in 11g (other than hash group by) that affect the order of rows returned by index scans. If I had to guess I'd say that the query was parallelized differently in 11g - certainly parallelized scans would come back out of order.
It's very dangerous in my opinion to rely on side effects like that to establish result set order. Oracle can always change it's internal algorithms and - unless you specify ORDER BY - is under no obligation to return rows in the same order. If you want them ordered you should specify ORDER BY.
Thanks a interesting and educative link. Can you please let me know the tool you have used in this page to show us the explain plan and statistics.
The tool I'm using is SQL Navigator - it's a Quest Software product built in the Melbourne Lab where I work. see http://www.quest.com/sql-navigator/
Guy,
I realise that this post is some 3 years old but I have done some experiements that I think prove that Oracle doesn't sort (in your example) 2.5 million rows in quite the same way as you have suggested. Please see my detailed response in my own blog entry.....just too much to post in a reply:
http://tonyhasler.wordpress.com/2012/06/11/ordering-non-sorting-aggregate-functions/
--Tony
Very nice article...Really helpful
We are getting HASH GROUP without any ORDER BY.
CPU usage is 12X that of SORT GROUP!!! Number of rows sorted is very small (typically < 10).