


Using SSD for a temp tablespace on Exadata
I seem to be getting a lot of surprising performance results lately on our X-2 quarter rack Exadata system, which is good – the result you don’t expect is the one that teaches you something new.
This time, I was looking at using a temporary tablespace based on flash disks rather than spinning disks. In the past – using Fusion IO PCI cards, I found that using flash for temp tablespace was very effective in reducing the overhead of multi-pass sorts:
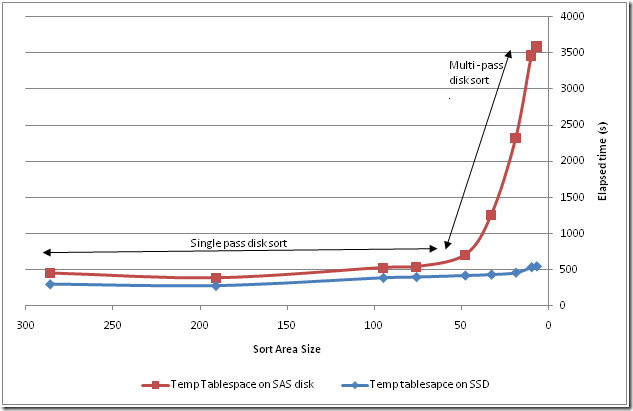
See (http://guyharrison.squarespace.com/ssdguide/04-evaluating-the-options-for-exploiting-ssd.html)
However, when I repeated these tests for Exadata, I got very disappointing results. SSD based temp tablespace actually lead to marginally worse performance:

Looking in depth at a particular point (the 500K SORT_AREA_SIZE point), we can see that although the SSD based temp tablespace has marginally better read times, it involves a significantly higher write overhead:

I can understand the higher read overhead (at least partially). It’s Yet Another time when sequential write operations to an SSD device have provided disappointing performance. However, it’s strange to see such poor read performance. How can a spinning disk serve blocks up at effectively the same latency an SSD?
So I dumped all the direct path read waits from a 10046 trace and plotted them logarithmically:

We can see in this chart, that the SDD based tablespace suffers from a small “spike” of high latencies between 600-1000 us (eg .6-1 ms). These are extremely high latencies for an SSD ! What could be causing them? Garbage collection being caused by the almost writes to the temp tablespaces? There was negliglbe concurrent activity on the system and the table concerned had flash cache disabled so for now that is my #1 theory.
For that matter, why are the HDD reads times so low? An average disk read latency of 500 us for a spinning disk is unreasonably low, is the storage cell somehow buffering temporary tablespace IO?
As always I’m wondering if there’s someone with more expertise in Exadata internals who could shed some light on all of this!
 Guy Harrison
Guy Harrison
Reader Comments (2)
Thanks for testing this scenario. Do you have iostat output from storage cells? Curious to know where most of the time was spent for flash devices (queue or service time).
Hi Guy,
Your findings are interesting but, if you'll allow, I have a few thoughts to share.
First, we need to remember that your X2 system has f20 Sun Flash cards (at least that is what came with the config). Those particular NAND cards were not easily mistaken for state of the art even in when they were current technology. I would expect I/O pathologies like stalls and what have you. Indeed, it is due to stalls that Oracle implemented redo writes that go to spinning and flash disk concurrently because every so often the spinning media wins the race.
Since your direct path reads are coming in at .5ms I wonder whether your TEMP active data set is really small? The HDD drives are downwind of an LSI controller that had DRAM cache on it. You should be able to log into a cell and use the megacli command to dump specs about the RAID card. It should be LSI 9261-8i which has 512MB of DDR2 SDRAM. So your 3 node cluster has 1.5GB of DRAM HDD cache. Maybe your I/O is being covered in that tier of cache?
Considering the life cycle of a direct path read on Exadata I'd say you might consider counting lucky stars that it is (supposedly) even under about 800us. I'm actually quite surprised. Your test must not be doing much total I/O because I think 1+ms would be more realistic considering how much usermode code, comms points, context switches there are along the way.
It should come as no surprise that I would recommend analyzing this storage with SLOB.
Exadata is good at a few things, great at fewer, bad at a lot and on par with conventional platforms for the remainder--which incidentally is the majority.