


Using SSD for a temp tablespace on Exadata
I seem to be getting a lot of surprising performance results lately on our X-2 quarter rack Exadata system, which is good – the result you don’t expect is the one that teaches you something new.
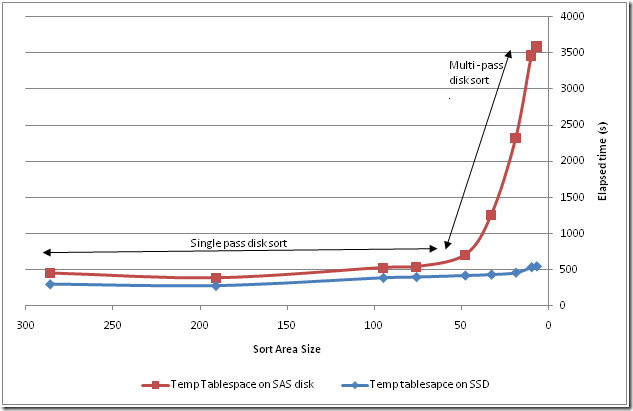
This time, I was looking at using a temporary tablespace based on flash disks rather than spinning disks. In the past – using Fusion IO PCI cards, I found that using flash for temp tablespace was very effective in reducing the overhead of multi-pass sorts:
See (http://guyharrison.squarespace.com/ssdguide/04-evaluating-the-options-for-exploiting-ssd.html)
However, when I repeated these tests for Exadata, I got very disappointing results. SSD based temp tablespace actually lead to marginally worse performance:

Looking in depth at a particular point (the 500K SORT_AREA_SIZE point), we can see that although the SSD based temp tablespace has marginally better read times, it involves a significantly higher write overhead:

I can understand the higher read overhead (at least partially). It’s Yet Another time when sequential write operations to an SSD device have provided disappointing performance. However, it’s strange to see such poor read performance. How can a spinning disk serve blocks up at effectively the same latency an SSD?
So I dumped all the direct path read waits from a 10046 trace and plotted them logarithmically:

We can see in this chart, that the SDD based tablespace suffers from a small “spike” of high latencies between 600-1000 us (eg .6-1 ms). These are extremely high latencies for an SSD ! What could be causing them? Garbage collection being caused by the almost writes to the temp tablespaces? There was negliglbe concurrent activity on the system and the table concerned had flash cache disabled so for now that is my #1 theory.
For that matter, why are the HDD reads times so low? An average disk read latency of 500 us for a spinning disk is unreasonably low, is the storage cell somehow buffering temporary tablespace IO?
As always I’m wondering if there’s someone with more expertise in Exadata internals who could shed some light on all of this!
 Guy Harrison
Guy Harrison




