


Optimizing the order of MongoDB aggregation steps
An updated version of this blog post can be found at https://www.dbkoda.com/blog/2017/10/14/Optimizing-the-order-of-aggregation-pipelines
MongoDB does have a query optimizer, and in most cases it's effective at picking the best of multiple possible plans. However it's worth remembering that in the case of the aggregate function the sequence in which various steps are executed is completely under your control. The optimizer won't reorder steps into the optimal sequence to get you out of trouble.
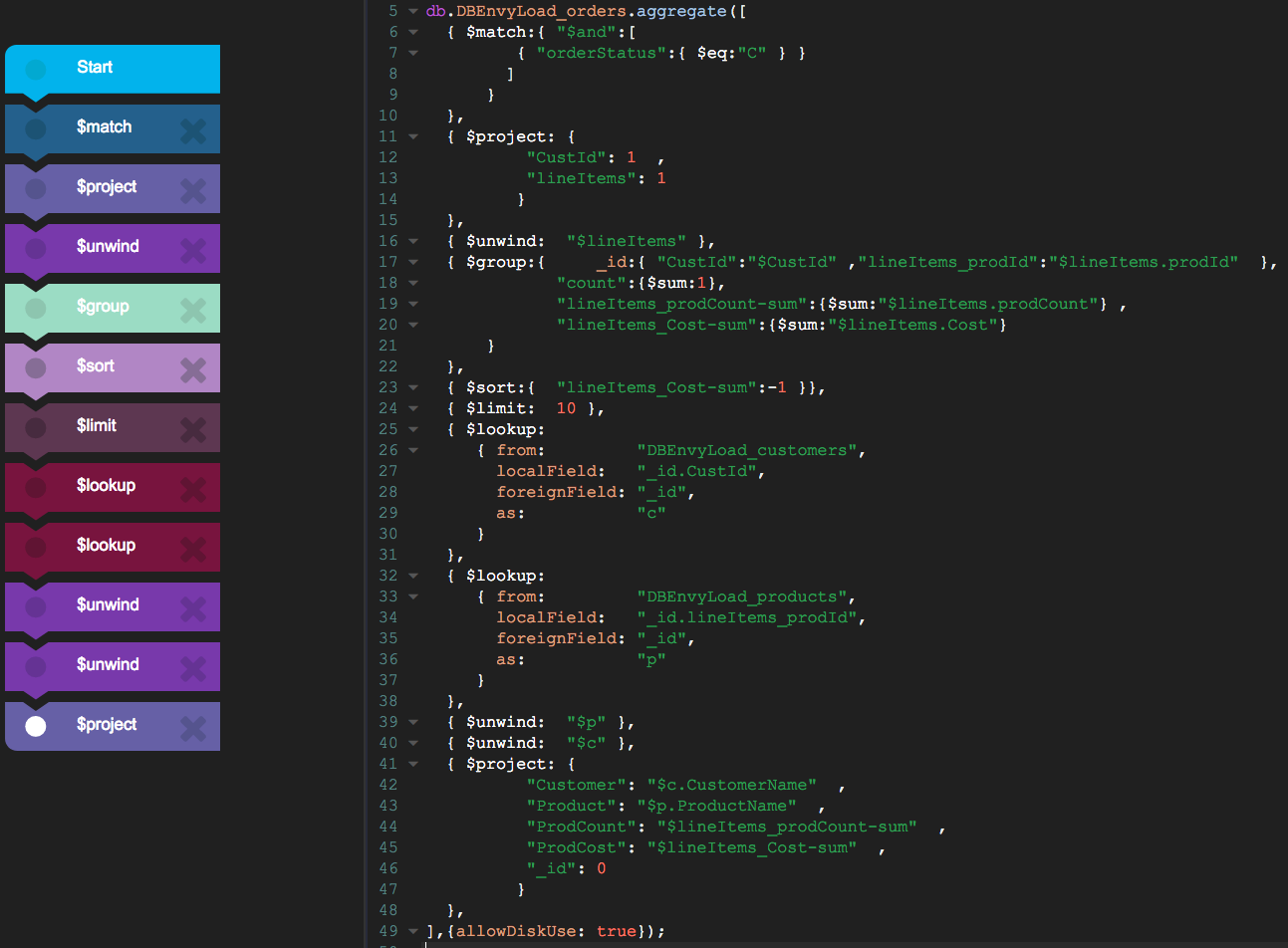
Optimizing the order of steps probably comes mainly to reducing the amount of data in the pipeline as early as possible – this reduces the amount of work that has to be done by each successive step. The corollary is that steps that perfom a lot of work on data should be placed after any filter steps.
Please go to https://medium.com/dbkoda/optimizing-the-order-of-aggregation-pipelines-44c7e3f4d5dd to read the rest of this post
 Guy Harrison
Guy Harrison
Reader Comments