


Bulk inserts in MongoDB
Like most database systems, MongoDB provides API calls that allow multiple documents to be inserted or retrieved in a single operation.
These “Array” or “Bulk” interfaces improve database performance markedly by reducing the number of round trips between the client and the databases – dramatically. To realise how fundamental an optimisation this is, consider that you have a bunch of people that you are going to take across a river. You have a boat that can take 100 people at a time, but for some reason you are only taking one person across in each trip – not smart, right? Failing to take advantage of array inserts is very similar: you are essentially sending network packets that could take hundreds of documents over with only a single document in each packet.
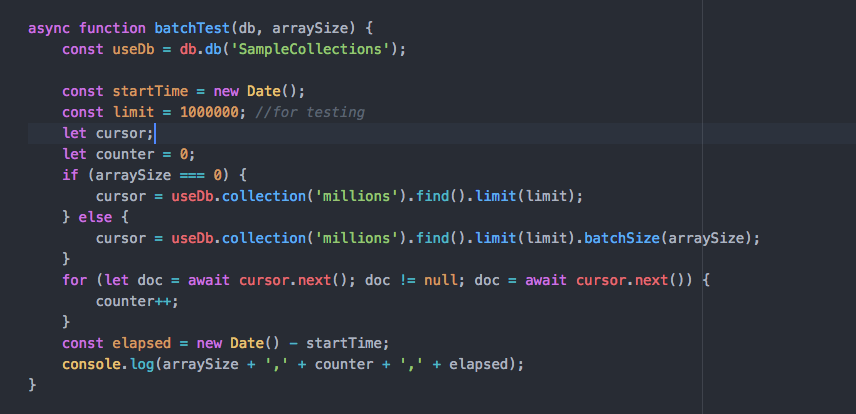
Optimizing bulk reads using .batchSize()
Read the rest of this post at https://medium.com/dbkoda/bulk-operations-in-mongodb-ed49c109d280
 Next Generation Databases, NoSQL
Next Generation Databases, NoSQL
Reader Comments