0.7.0 is the second public release of dbKoda and our first post-MVP release. With the MVP (Minimal Viable Product) we definitely nailed the "M" criteria, and in this release we've pushing harder on the "V" side of the equation.
As with 0.6, dbKoda is a free, open source, Vegan product made by groovy people in Melbourne Australia. It's licensed under the AGPL 3.0.
As well as many bug fixes, brand new bugs and performance improvements, we added the following features:
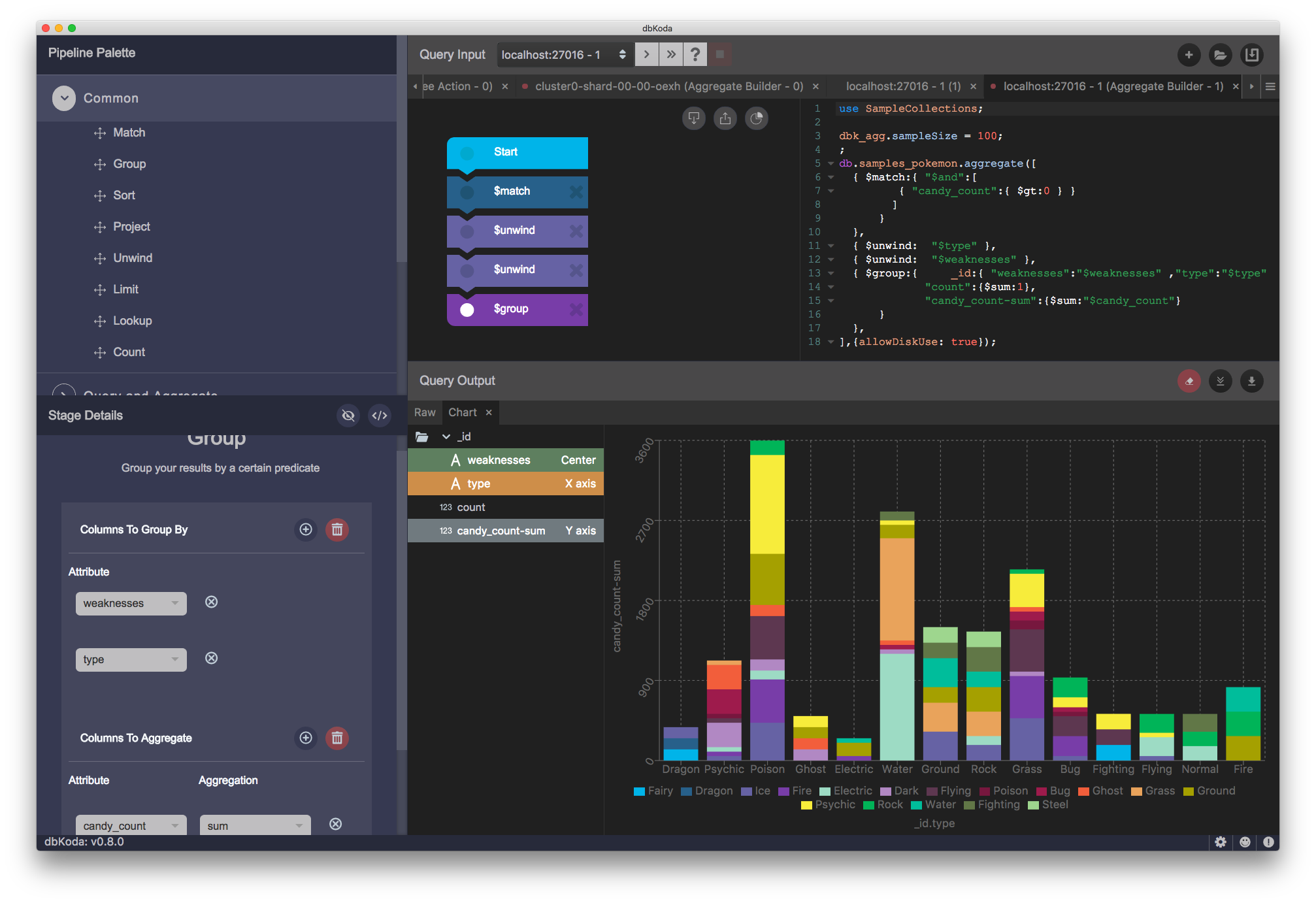
Aggregation Builder
At this years MongoDB conference, we spotted one of the MongoDB engineers wearing a "Aggregate() is the new Find()" T-shirt. It's funny, because it's true: almost every non-trivial MongoDB data retrieval operation requires an aggregation pipeline. Features such as joins and graph lookups can only be done through the aggregation framework and under the hood features such as the BI connector depend on aggregation as well.
As anybody who has ever written an aggregation framework pipeline knows, the process is very tedious and error prone - matching braces and getting syntax exactly right is difficult. So in dbKoda 0.7 our aggregation builder allows you to drag and drop pipeline elements and use file in the blank forms to construct complex pipelines. It's amazing how quickly you can build up a complex pipeline using the builder - a video on our youtube channel shows me building up a non-trival pipeline in under 60 seconds: so try it out!
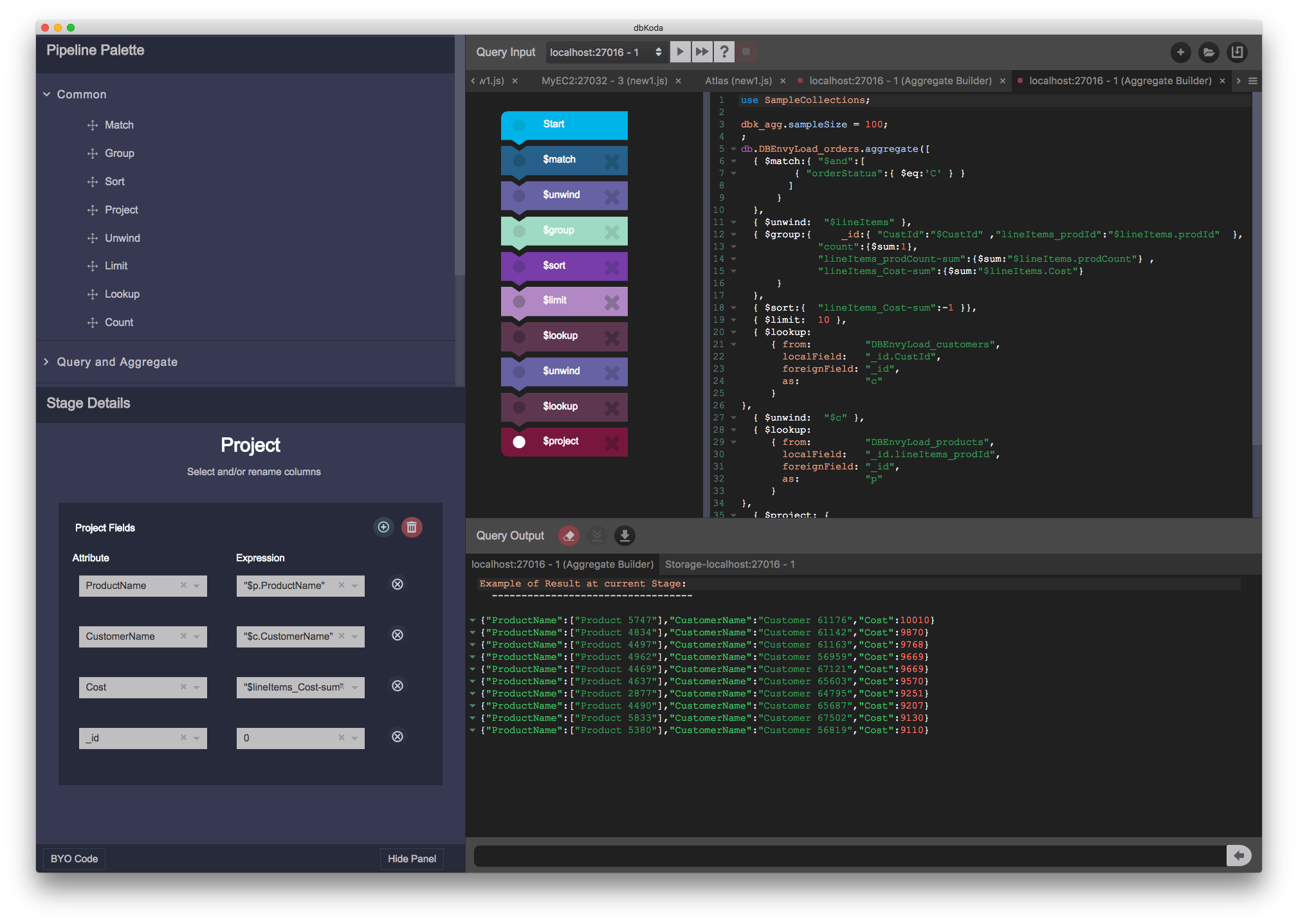
(click to enlarge)
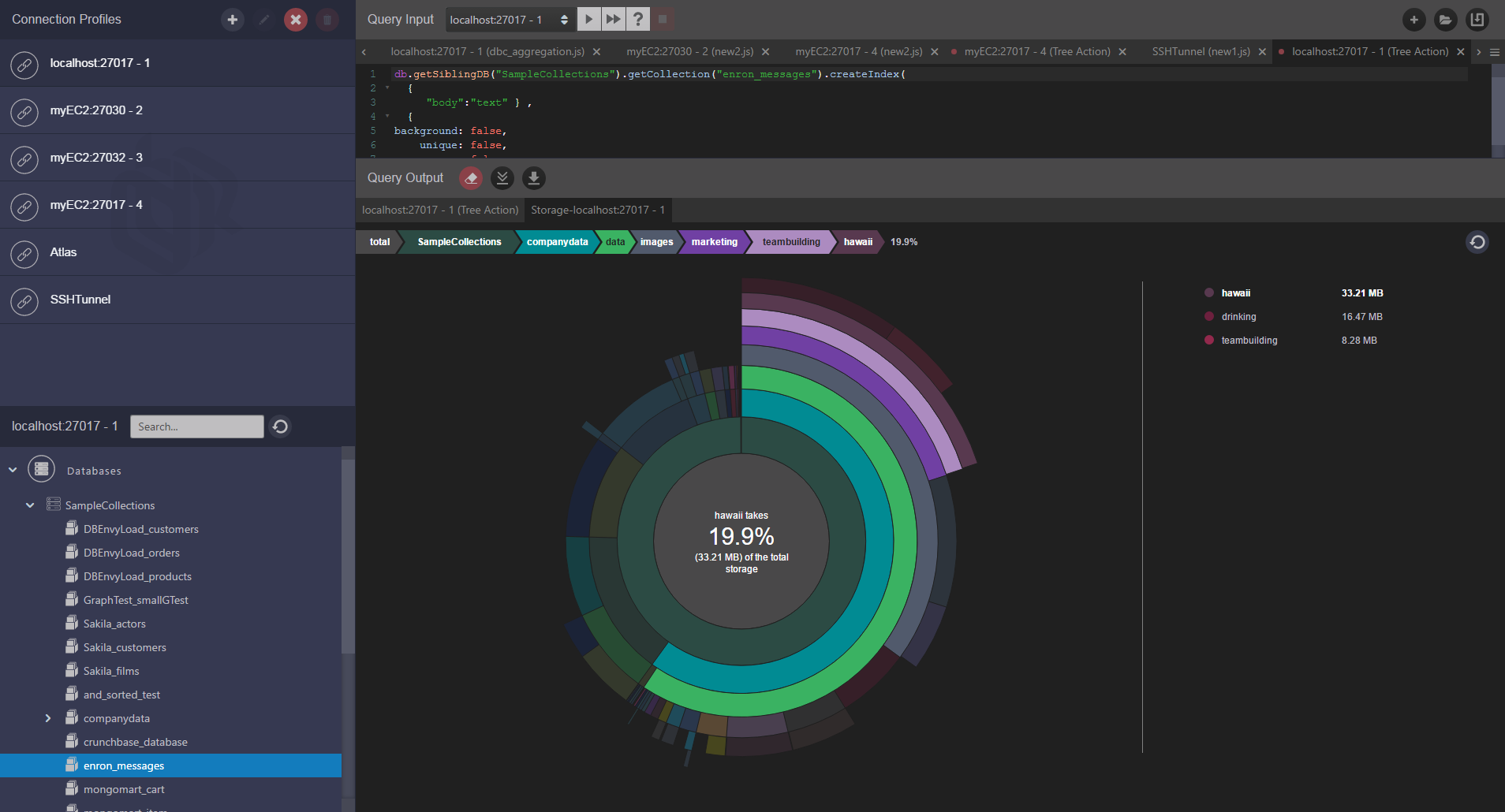
Storage Drilldown
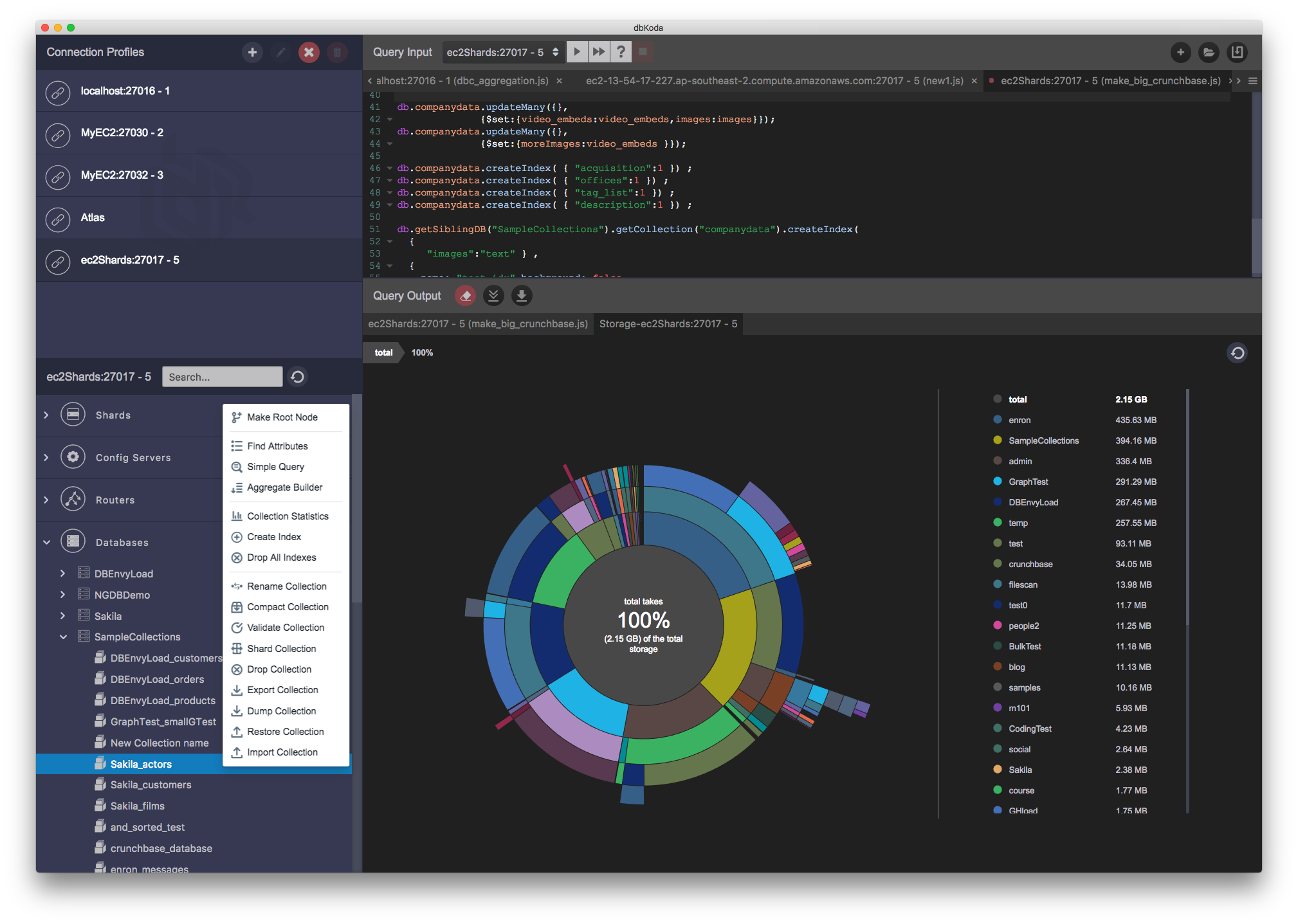
MongoDB can tell you how much space is used up in databases, collections and indexes, but it is not so good at breaking down space within a document. Because MongoDB's document model supports nested arrays of documents, it’s often the space used within a collection that is the most important thing to identify. For instance, typical reasons for space blowouts MongoDB are unbounded arrays of nested collections.
dbKoda's storage drilldown breaks down space used within databases, collections, indexes and shows you how storage is used within a collection. It does this in an intuitive graphical presentation that allows you to drill in and out of nested documents.
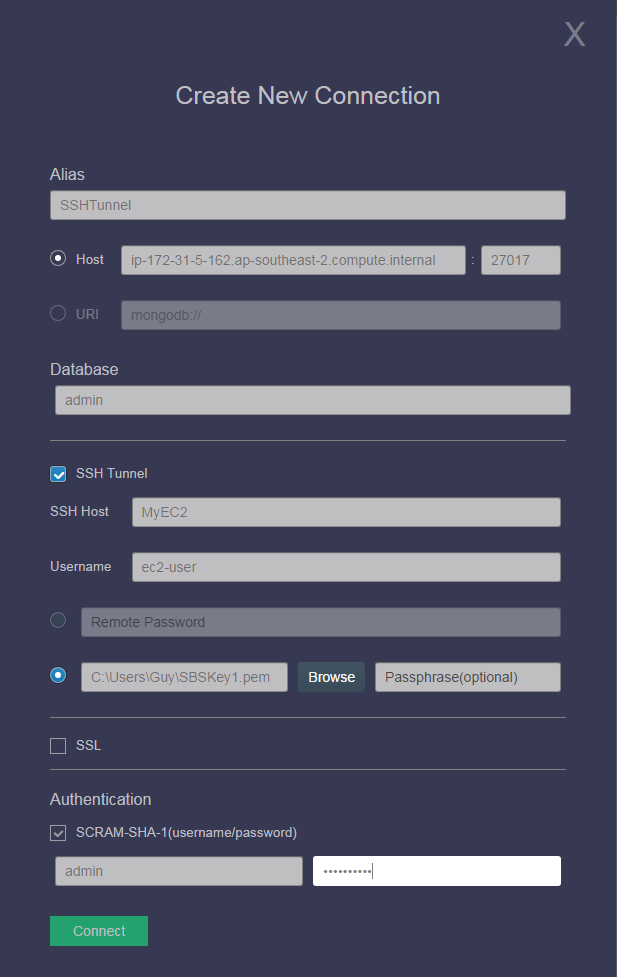
SSH tunneling connections
We were all horrified at the explosion of ransomware attacks on MongoDB databases early in 2017. The root cause of the security vulnerabilities in these databases was the failure to correctly create authenticated users, but it is also true that you take your life in your hands whenever you expose a database port to the public Internet. For this reason it’s often the best practice to leave database ports open only within a walled garden. If you want to perform day administration using tools such as dbKoda then you use SSH tunneling to establish a connection.
This FAQ entry describes SSH tunnelling and how it is used in dbKoda. Put simply, you can now specify an intermediate host which offers you SSH connectivity and use that host to forward database requests to the secured MongoDB server.
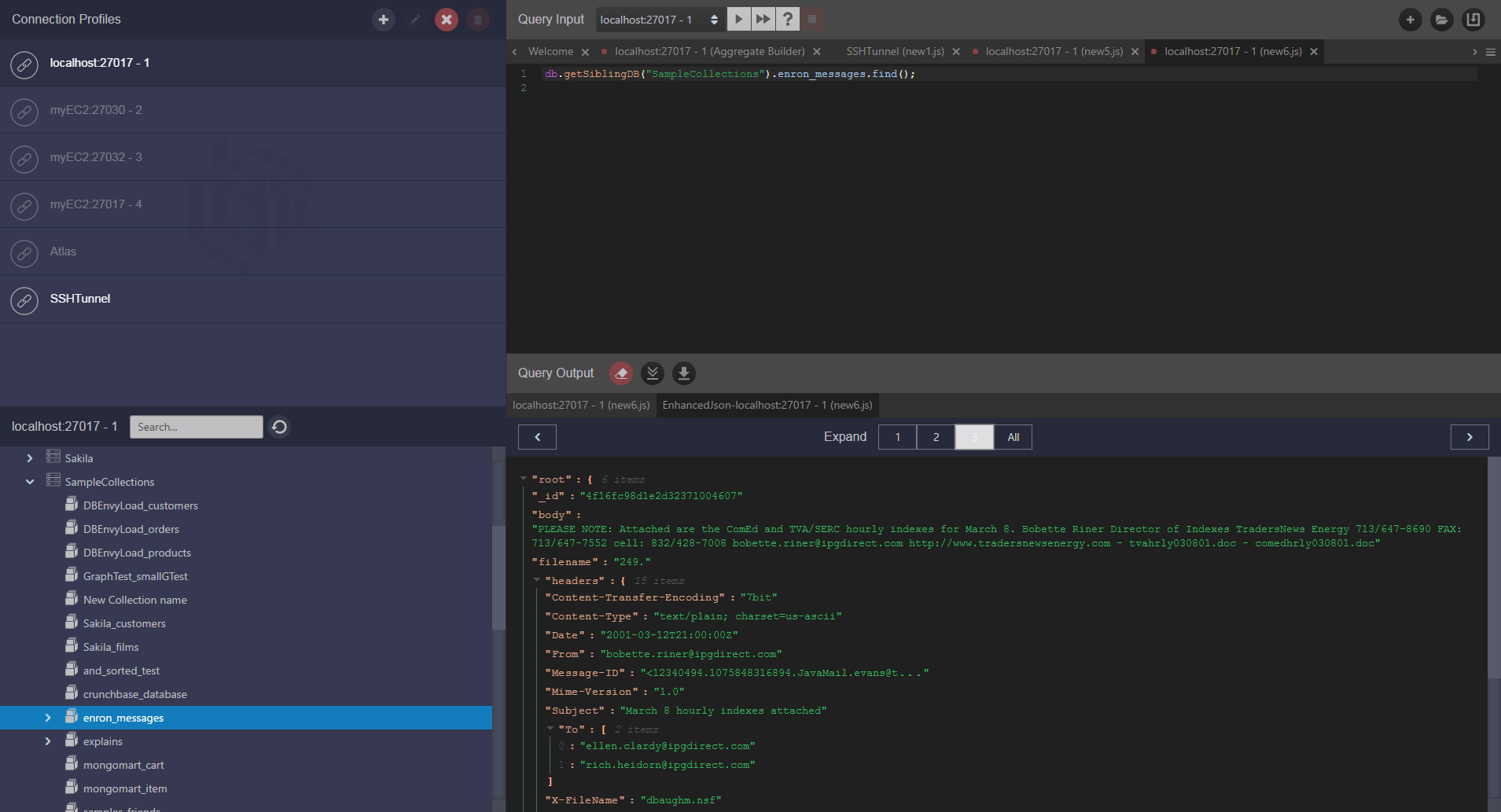
Enhanced JSON viewer
Complex JSON documents can be difficult to read. By default dbKoda will display JSON output as it would appear in the MongoDB shell. We aspire to complete shall compatibility after all! In 0.7, we offer an enhanced trace and your that allows you to examine JSON documents with multiple levels of detail, allowing you to expand collapse subdocuments and long strings. This facility is available wherever JSON output is displayed on the product, by right clicking and choosing “enhanced JSON output”.
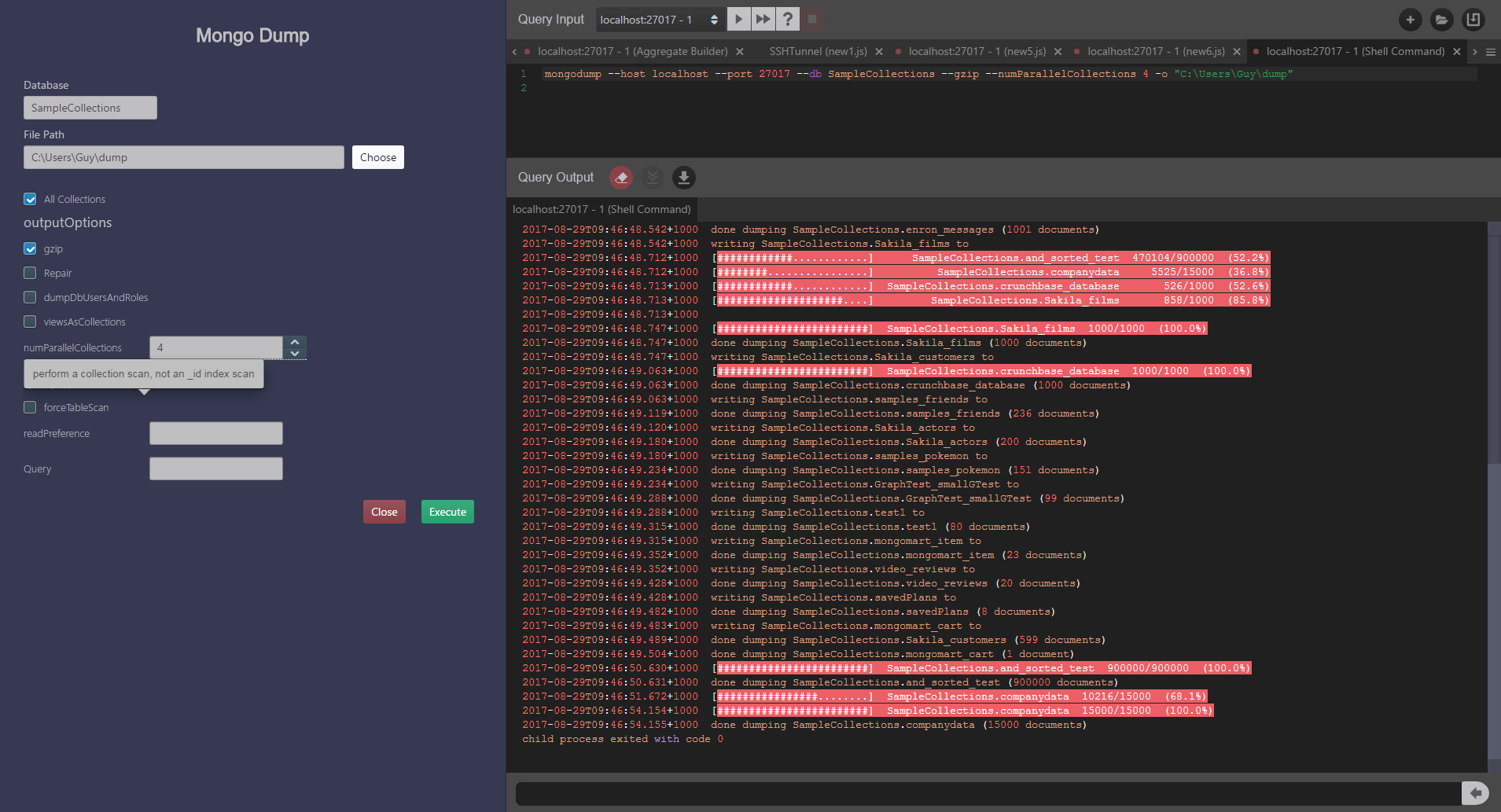
Export/Import
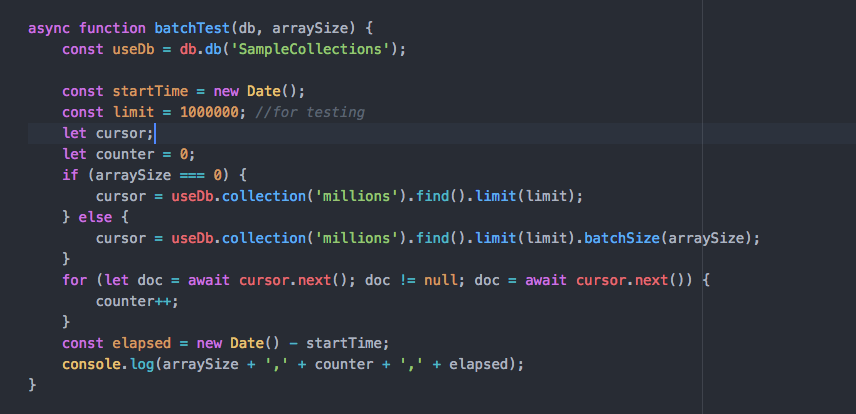
0.7 allows you to load or unload data to or from your MongoDB server. This facility provides GUI access to the `mongodump`, `mongorestore`, `mongoexport` and `mongoimport` commands.
Enhanced performance on windows
In 0.6, there were some performance issues when very large amounts of data were displayed in our output panel. We worked hard to resolve these and now believe that performance on windows will match performance on Linux and Mac.
Summing up
We added a lot of cool functionality in this release - we hope you'll try it out and let us know what you think. Download dbKoda from www.dbkoda.com and let us know what you think at our support site.



 This release contains lots of bug fixes, the ability to view data as a chart or in tabular form, and the ability to convert mongodb shell commands into Node.js syntax. Check out the blog post outlining all the new features at https://www.dbkoda.com/blog/2017/11/06/New-Features-in-dbKoda0.8
This release contains lots of bug fixes, the ability to view data as a chart or in tabular form, and the ability to convert mongodb shell commands into Node.js syntax. Check out the blog post outlining all the new features at https://www.dbkoda.com/blog/2017/11/06/New-Features-in-dbKoda0.8 Guy Harrison
Guy Harrison