


The 11GR2 IGNORE_ROW_ON_DUPKEY_INDEX hint
One of the strangest new features in 11GR2 is the new IGNORE_ROW_ON_DUPKEY_INDEX hint. When this hint is applied to an INSERT statement, any duplicate key values that are inserted will be silently ignored, rather than causing an ORA-0001 error.
Why is this so strange? Mainly because unlike almost all other hints, this hint has a semantic effect: it changes the actual behavior - not just the optimization - of the SQL. In my opinion, clauses that affect the actual data effect of the SQL should be contained in official SQL syntax, not embedded in a comment string as a "hint". The Oracle documentation acknowledges the uniqueness of the hint:
Note:
The CHANGE_DUPKEY_ERROR_INDEX, IGNORE_ROW_ON_DUPKEY_INDEX, and RETRY_ON_ROW_CHANGE hints are unlike other hints in that they have a semantic effect. The general philosophy explained in "Hints" does not apply for these three hints.
Given all that, I'd be reluctant to use such a hint unless there was a compelling performance advantage. So, let's see if there's any performance justification for this strange hint.
Usage
We can use the hint in circumstances in which we expect that an insert may encounter a duplicate key on index error. Traditionally, we have two ways of avoiding this scenario. The most familiar is to code an exception handler that handles the duplicate key error:
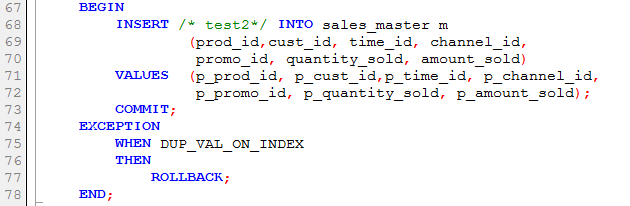
Another common approach is to check to see if there is a matching value before the insert:
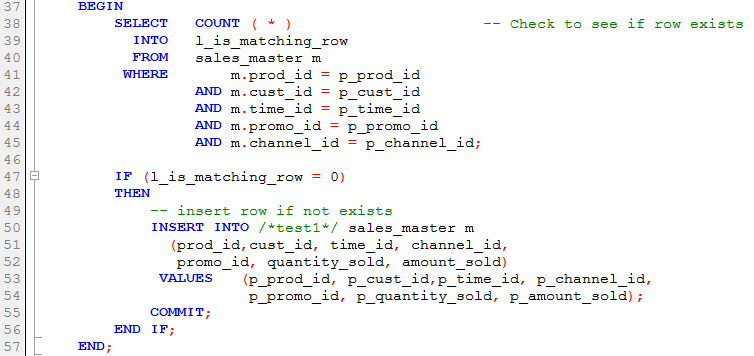
This doesn't totally eliminate the possibility of an ORA-0001, since a row could get inserted between the SELECT and the INSERT - so you still might want to have an exception handler (or merge the SELECT into the INSERT). In any case, the exception handler will likely not be invoked very often with the above approach.
The IGNORE_ROW_ON_DUPKEY_INDEX approach requires merely that we add a hint referring to the table alias and optionally the index for which we anticipate ORA-0001:
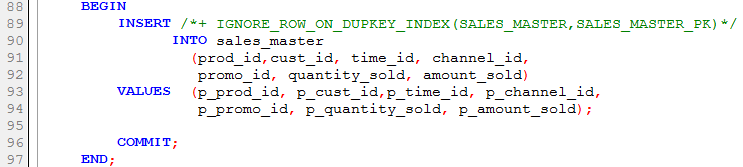
As with all hints, a syntax error in the hint causes it to be silently ignored. The result will be that ORA-00001 will be raised, just as if no hint were used.
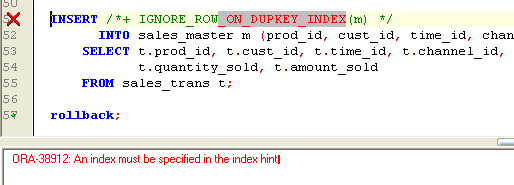
However, unlike most hints, you might actually generate an error if you don't specify a valid index. As in this example:
Performance implications
So, which approach is faster? I inserted about 600,000 rows into a copy of the SALES table. About 1/2 the rows already existed. I traced each of the programming approaches illustrated above:
- Issue a select to see if there is already a matching value and only insert if there is not.
- Issue an INSERT and use an EXCEPTION handler to catch any duplicate values
- use the IGNORE_ROW_ON_DUPKEY_INDEX hint
Here's the elapsed times for each approach. Not that these times only include SQL statement execution time - the PL/SQL time (loop and collection handling, etc) is not shown:
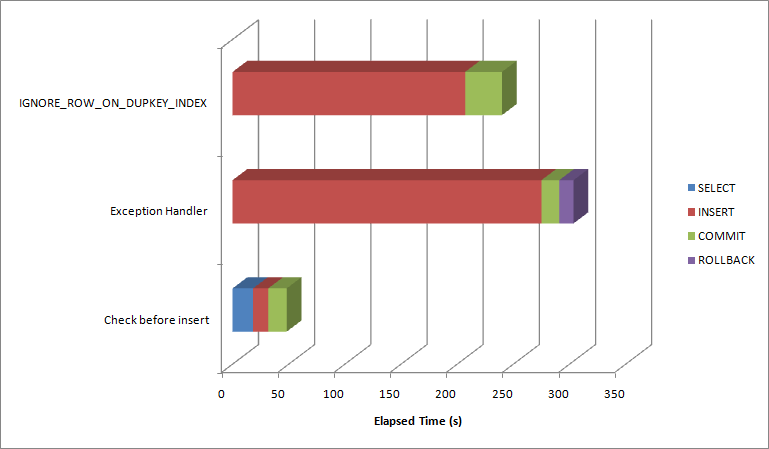
It's clearly much more efficient to avoid insert duplicates than to insert them and handle the exception or use the IGNORE_ROW_ON_DUPKEY_INDEX hint. Rollbacks - explicit or implicit statement level rollbacks - are expensive and should generally be avoided. The IGNORE_ROW_ON_DUPKEY_INDEX hint does seem to be a little faster than handling the exception manually, but it's still far more efficient to avoid inserting the duplicate in the first place.
Use with caution
As well as the other limitations of this hint, there's also a significant bug which causes an ORA-600 [qerltcInsertSelectRop_bad_state] if you try to perform a bulk insert with the hint enabled:
 I've raised an SR on this issue.
I've raised an SR on this issue.
Conclusion
It's an odd idea to have a hint that affects the functionality rather than the performance of a SQL statement and this alone would make me avoid the hint. However, in addition to that reservation, the hint does not seem to offer a very significant performance advantage and in the initial release of 11GR2 is associated with some significant bugs.
 Guy Harrison
Guy Harrison
Reader Comments (7)
Hi Guy,
I hit the same bug for testing the performance comparison with the technique described here
http://www.colloperate.com/2009/12/oracle-is-strange.html
How did you do the test, did you insert row by row in a cursor to get around from the bug ?
Yes, the tests were done with single row inserts in a loop for 600,000 rows. When Oracle fixes the ORA-600 I'll do my original tests which were for batch inserts.
Hi Guy,
The hint is "weird" because my understanding is that its designed for a specific purpose, namely, for within a cross-edition trigger. Lets say you've just created a new edition "E" which uses a new table T1 (instead of the old table T). Now you are now running an one-off insert statement in the new edition to populate that new table T1 with the contents of T (via the cross edition trigger). Whilst you're doing this of course, people in the base edition might still be firing off the same cross-edition trigger as they use the running application. In this case, you want your one-off insert not to block or crash, but simply bypass the already migrated row. Hence the hint...
Cheers
Connor
Thanks Connor. That makes sense.
Guy
Doc says "This hint improves performance and ease-of-programming when implementing an online application upgrade script using edition-based redefinition."
Is there any performance loss when no constraint violations actually occur during insert operation?
The problem with the select-before-insert approach is that it doesn't work with concurrent inserts. If the insert is being done by another session whose transaction is running, the select will return 0 rows and the insert will raise an error.
On the other hand the problem with performance may be caused by the rollback being executed in the two options that try the insert without checking previously if the row exists. I'm quite sure that raising a rollback in case the select returns any row would also have a big impact on performance.