


Best practices with Python and Oracle
This is the third in a series of postings outlining the basics of best practices when coding against Oracle in the various languages. In Oracle Performance Survival Guide (and in it's predecessor Oracle SQL High Performance Tuning) I emphasise the need to use bind variables and array processing when writing Oracle programs. The book provides examples of both in PL/SQL and Java, while these postings outline the techniques in other languages.
Previous postings covered .NET languages and perl.
The Python code for the examples used in the posting is here.
I became interested in python a few years back when I read the article Strong Typing vs Strong Testing in Best Software Writing and from various other sources that sjggested that Python was a more modern and robust scripting language than Perl (and superior to Java for that matter). I dabbled with Python and thought about dropping perl as my scripting language of choice but in the end stuck with perl and Java as my primary languages because: (a) decades of perl experience were going to be too hard to replicate in Python and (b) the database drivers for python were not universally of the same quality as perl.
Nevertheless, Python is an excellent language for Oracle development and utilities and the cx_oracle driver fully supports best coding practices for Oracle.
Bind Variables
As with most languages, it's all too easy to concatenate literals - creating a unique SQL which mush be re-parsed - rather than using the more efficient bind variable approach. If anything, it's even easier in Python, since Python's string substitution idiom looks very similar to bind variables.
For instance, in this fragment, the "%d" literal in the SQL text represents the substitution value for the query:

Of course, if you are at all familiar with Python you'll know that the "%" operator substitutes the values in the subsequent list into the preceding string - so this example creates many unique SQL statements leading to high parse overhead; and possibly to library cache latch or mutex contention.
The cursor execute method allows you to specify bind variables as a list following the SQL, as in this example:

In line 129 we define a named bind variable ":x_value". Within the execute procedure (line 130) we assign the bind variable to the value of the python variable "i".
There's a couple of different styles of using bind variables in python. You can use positional parameters (eg ":1",":2", etc) and pass in a python list that contains the values in sequence and - as we shall see soon - you can bind arrays.
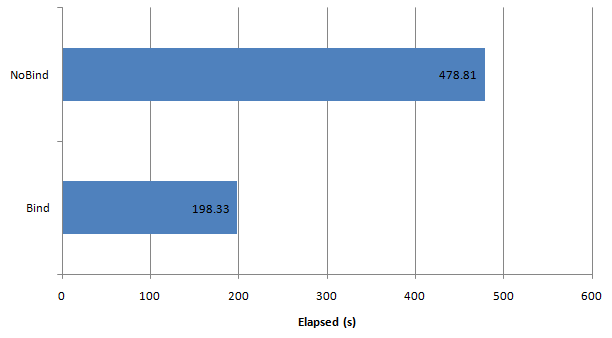
As with any programming language, using bind variables improves performance by reducing parse overhead and library cache latch or mutex contention. The above SQL is about as simple as you can get, so parse overhead reductions should be modest. As the only active session on my (local laptop) database, library cache contention would not be expected either. Nevertheless, elapsed time even in this simple example reduced by more than 1/2 when bind variables were used.
Array Fetch
Fetching rows in batches generally reduces elapsed time for bulk selects by up to a factor of 10. Array fetch works to improve performance by reducing network round trips and by reducing logical reads.
Like most modern interfaces, Python with cx_oracle will do some level of array fetch for you, even if your program handles rows and at a time. So in the example below, it looks like we are fetching rows one at a time:

Using SQL trace, we can see that Python in fact fetched rows in batches of 50 (this is shown using Spotlight on Oracles trace file analyzer, but you can deduce the same thing from tkprof output):
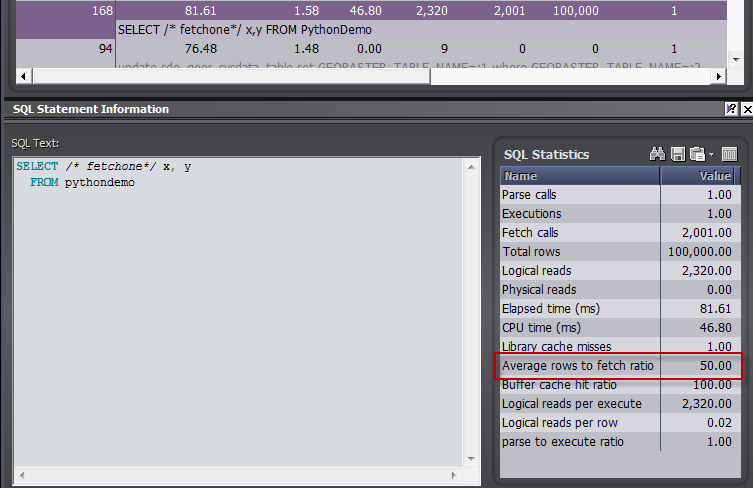
You can adjust or view the array size through the arraysize cursor property. Here we foolishly set the arraysize to 1:
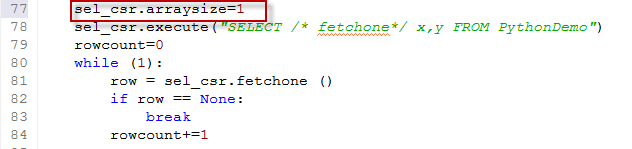
Python provides fetchmany() and fetchall() calls in addition to the "fetchone" call used above. While these do affect the handling of the result set on the python side, the arraysize variable continues to control the size of the array fetch actually sent to Oracle. The fetchall() call is more efficient in some ways, but requires that you have enough memory on the client side to hold the entire result set in memory:

Fetchmany() let's you handle the results in batches:

The arraysize cursor property determines how many rows are in each set, so with fetchmany() the python code corresponds most closely to the underlying Oracle processing logic.
For 500,000 rows, here's the performance of each of the approaches we've tried so far:
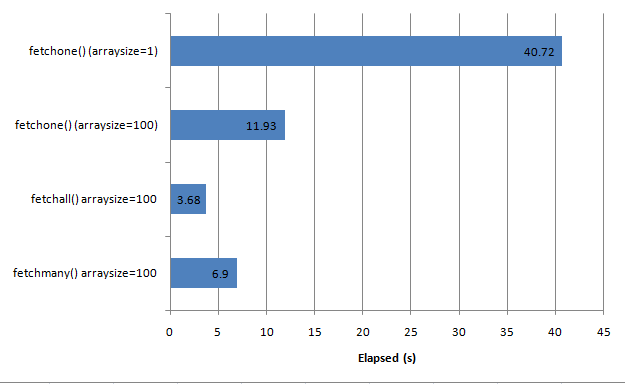
Although fetchall() performed best in this example, it may backfire for very massive result sets, because of the need to allocate memory for all of the data in the result set. fetchmany() may be the best approach if you're not sure that the result set is small enough to fit comfortably in memory.
Array insert
Array insert has similar performance implications as array fetch, but it harder to program and does not happen automatically. The "natural" way to perform inserts is probably to loop through the rows and assign them one at a time:
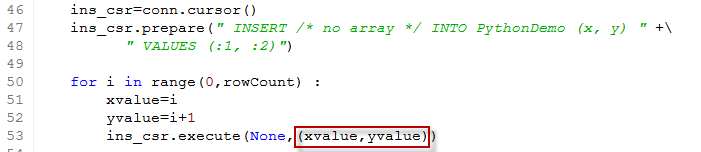
The values to be inserted are supplied as a Python list which is bound to the positional bind variables (":1, :2") defined in the SQL. In this example we used the prepare method to create the SQL once before executing it many times. This is not a bad practice, but doesn't seem to have any impact on parse overhead: Python only reparses the SQL when the SQL text changes.
To perform an array insert, we create a "list of lists" which defines our array to be inserted. We then call the executemany() method to insert that array:
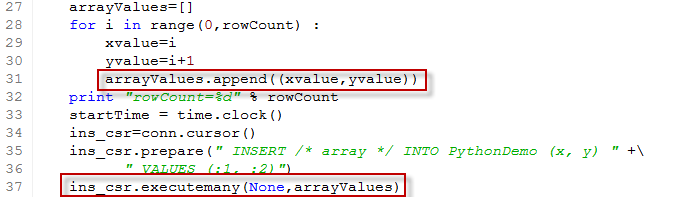
Each entry in the arrayValues list is itself a list that contains the values to be bound.
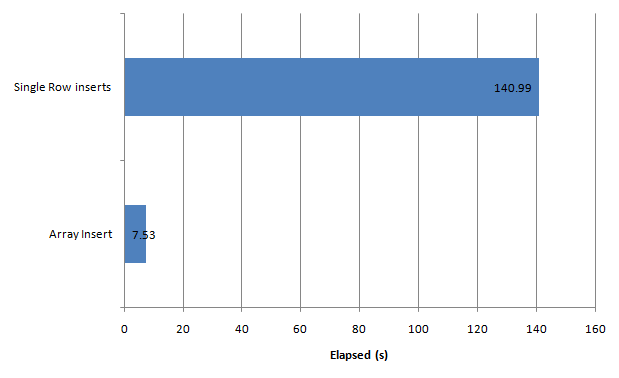
As usual, the performance improvements are fairly remarkable. The chart above compares the time to insert 500,000 rows using array insert vs. single row inserts.
Conclusion
The basics of good practice in Python when working with an Oracle database are much the same as those for other languages:
- Use bind variables whenever possible
- Array fetch is performed automatically, but you can tweak it to get better performance
- Array insert requires manual coding but is definitely worth it
 Guy Harrison
Guy Harrison
Reader Comments (6)
i like this
Thanks for shedding some light ;o)
Thanks for the coding.
It is helpful.
awesome blog harrison..... thanks for this blog....
Hi
Curious. maybe you have a suggestion. I run a query directly on the DB using sqlplus, and it runs in 3.5mins, run the same query in Python 2.7 using arraysize of 50 and it takes just over 9mins. Have you got any ideas how to speed it up?
QUERY: set timing on
select sw.inst_id, sw.sid, sw.state, sw.event, sw.seconds_in_wait seconds, sw.p1, sw.p2, sw.p3, sa.sql_text last_sql
from gv$session_wait sw, gv$session s, gv$sqlarea sa
where sw.event not in ('rdbms ipc message','smon timer','pmon timer','SQL*Net message from client','lock manager wait for remote message','ges remote message', 'gcs remote message', 'gcs for action', 'client message','pipe get', 'null event', 'PX Idle Wait', 'single-task message','PX Deq: Execution Msg', 'KXFQ: kxfqdeq - normal deqeue','listen endpoint status','slave wait','wakeup time manager') and sw.seconds_in_wait > 0 and (sw.inst_id = s.inst_id and sw.sid = s.sid)
and (s.inst_id = sa.inst_id and s.sql_address = sa.address) order by seconds desc;
Python code:
qry=" ".join(
["select sw.inst_id, sw.sid, sw.state, sw.event, sw.seconds_in_wait seconds, ",
"sw.p1, sw.p2, sw.p3, sa.sql_text last_sql ",
"from gv$session_wait sw, gv$session s, gv$sqlarea sa ",
"where sw.event not in ",
"('rdbms ipc message','smon timer','pmon timer', ",
"'SQL*Net message from client','lock manager wait for remote message', ",
"'ges remote message', 'gcs remote message', 'gcs for action', 'client message', ",
"'pipe get', 'null event', 'PX Idle Wait', 'single-task message', ",
"'PX Deq: Execution Msg', 'KXFQ: kxfqdeq - normal deqeue', ",
"'listen endpoint status','slave wait','wakeup time manager') ",
"and sw.seconds_in_wait > 0 ",
"and (sw.inst_id = s.inst_id and sw.sid = s.sid) ",
"and (s.inst_id = sa.inst_id and s.sql_address = sa.address) ",
"order by seconds desc "])
if debug: logger.info(qry)
run_query("Waiting Sessions",qry,0)
Not knowing how the internals of cx_oracle I've been getting a connection once, and then passing that around my program for the various db calls.
connection = get_connection(config)
results = my_function_1(connection, arg_1, arg_2)
other_results = another_function_1(connection, arg_1, arg_2)
Is this the right approach or would it be better to get a new connection in each function call?
Does the api somehow know a connection is already open and hand you back that one?
Thanks