Using the Oracle 11GR2 database flash cache
Oracle just released a patch which allows you to use the database flash cache on Oracle Enterprise Linux even if you don't have exadata storage. The patch is the obscurely named:
- 8974084:META BUG FOR FLASH CACHE 11.2PL BUGS TO BACKPORT TO 11.2.0.1 OEL
Once you install the patch you can use any old flash device as a database flash cache. Below I've documented some initial dabbling on a very old server and a cheap usb flash device. The results are not representative of the performance you'd get on quality hardware, but are still interesting, I think.
Setup and configuration
If, like me, you just want to experiment using an USB flash device, then you first need to get that device mounted. On my test machine I created a directory "/mnt/usbflash" then created an /etc/fstab entry like this:
/dev/sda1 /mnt/usbflash vfat noauto,users,rw,umask=0 0 0
On your system you might need to change "/dev/sda1" to another device depending on how your fixed disks are configured. You should then be able to mount the flashdrive by typiing "mount /dev/sda1". Make sure that the mount point is writable by oracle (chmod 777 /mnt/usbflash).
Once mounted, you configure the flash cache by setting the parameters DB_FLASH_CACHE_FILE and DB_FLASH_CACHE_SIZE. My settings are shown below:
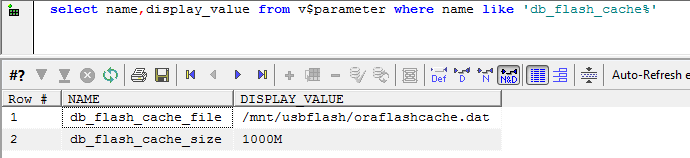
Note that the value of DB_FLASH_CACHE_FILE needs to be a file on the flash drive, not the flash drive mount point itself.
Once these parameters are set, the flash cache will be enabled and will act as a secondary cache to the buffer cache. When a block is removed from the primary cache, it will still exist in the flash cache, and can be read back without a physical read to the spinning disk.
Monitoring
There's a few ways to examine how the flash cache is being used. Firstly, V$SYSSTAT contains some new statistics showing the number of blocks added to the cache and the number of "hits" that were satisfied from cache (script here):
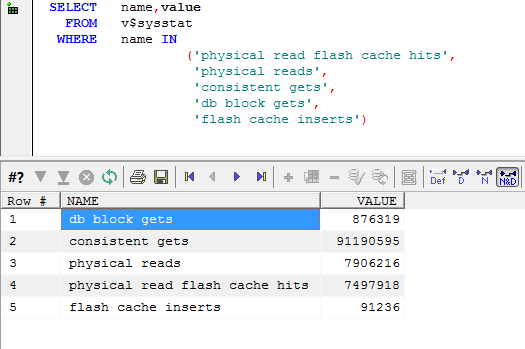
Some new wait events are now visible showing the waits incurred when adding or reading from the flash cache. Below we see that 'db flash' waits are higher than 'db file sequential read', though reads from the flash cache are much quicker than reads from disk (but there are a lot more of them):
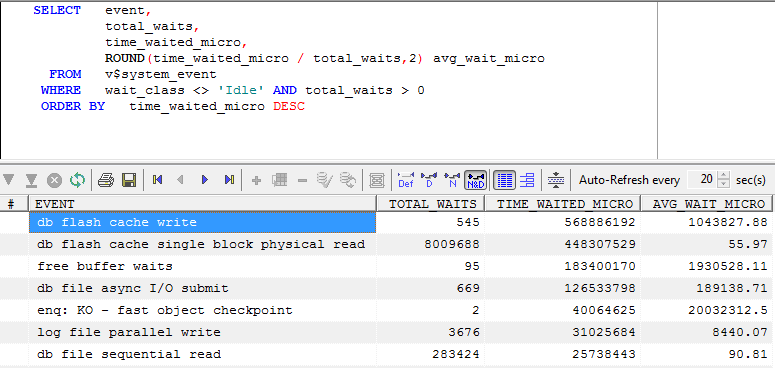
Now, remember that I could not have picked worst hardware for this test - an old two CPU intel box and a cheap thumb drive. Even so, it's remarkable how high the write overhead is in comparison to the total time. Although the flash reads save time when compared to db file sequential reads, the overhead of maintaining the cache can be high because flash based SSD has a relatively severe write penalty.
All flash-based Solid State Disk have issues with write performance. However, cheap Multi Level Cell (MLC) flash take about 3 times as long to write as the more expensive Single Level Cell (SLC). When flash drives are new, the empty space can be written to in single page increments (usually 4KB). However, when the flash drive is older, writes typically require erasing a complete 128 page block which is very much slower. My cheap USB drive was old and MLC, so it had very poor write performance. But even the best flash based SSD is going to be much slower for writes than for reads, and in some cases using a flash cache might slow a database down as a result. So monitoring is important.
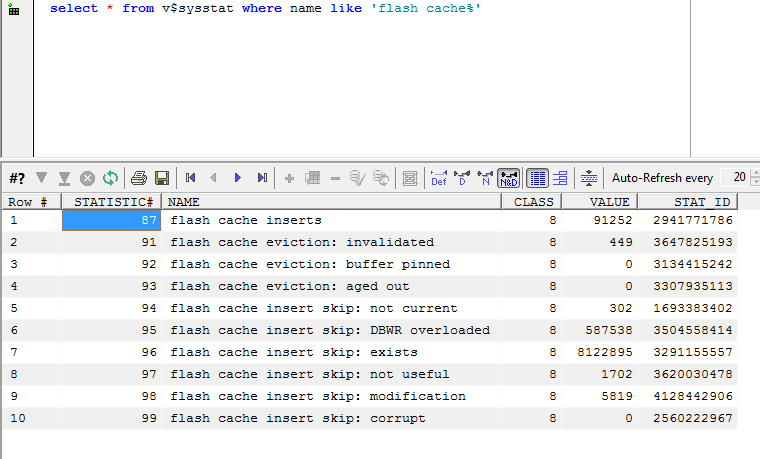
There's a couple of other V$SYSSTAT statistics of interest:
To examine the contents of the cache, we can examine the V$BH view. Buffers in the flash cache have STATUS values such as 'flashcur', allowing us to count the buffers from each object in the main buffer cache and in the flash cache (script is here):
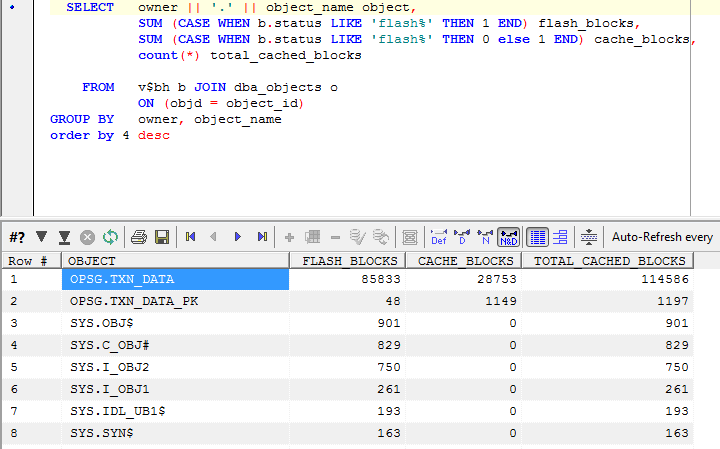
In this case, the TXN_DATA table has 85,833 blocks in the flash cache and 28,753 blocks in the main buffer cache.
Conclusion
I was happy to get the flash cache working, even with this crappy hardware. I'm really happy that Oracle opened this up to non-exadata hardware.
I'll be getting a better setup soon so that I can see how this works with a decent commerical SSD flash drive.
I'm a big believer in the need for a hierarchy of storage ideally including at least two layers - one for mass storage, the other for fast retrieval. We should be cautious however, because the flash write penalty may result in performance problems similar to those we've seen with RAID5.
 Guy Harrison
Guy Harrison