Important note: I wrote this post based on research with the 11gR2 beta. After posting it I discovered that the implementation of columnar compression was restricted in the production release. See the end of the post for important errata (and apologies).
We often think of compression as being a trade off between performance and storage: compression reduces the amount of storage required, but the overhead of compressing and decompressing makes things slower. However, while there is always some CPU overhead involved in compression the effect on table scan IO can be favourable, since if a table is reduced in size it will require fewer IO operations to read it.
Prior to 11g, table compression could only be achieved when the table was created, rebuilt or when using direct load operations. However, in 11g, the Advanced Compression option allows data to be compressed when manipulated by standard DML. Compression becomes even more attractive in 11gR2 because we can use columnar compression to get much higher compression levels than were previously possible.
Column-oriented databases and columnar compression
One of the key advantages of columnar databases such as Vertica is that they can get much higher compression ratios than are normally possible for traditional row-oriented databases.
The traditional RDBMS implementation – including Oracle – is to store all data for a given row in the same block. This might be might be optimal for OLTP operations – create an entry, query an entry, change an entry – but is not optimal for many data warehousing and BI query scenarios. In these scenarios storing the data for a specific column in the same block is far more effective, since data warehousing queries usually aggregate within columns and across rows.
Mike Stonebraker – pioneer of relational databases and one of the creators of Postgress – and his team proposed a new model for column-centric databases called C-Store in 2005. C-Store is a SQL-based database which uses a column-oriented architecture to optimize data warehousing activities. I wrote about C-Store and other next-generation database proposals in this DBTA article.
One of the big advantages of column-oriented databases is that very high compression rates can be achieved. Compression works best when repeated patterns are present. The repetition within columns is almost always far greater than the repetition within rows. For instance a SURNAME column can be expected to have many repeated entries, whereas there will be little or no repetition between a SURNAME and a DATE_OF_BIRTH column. Column orientation therefore allows for very high compression ratios to be achieved with only modest CPU requirements.
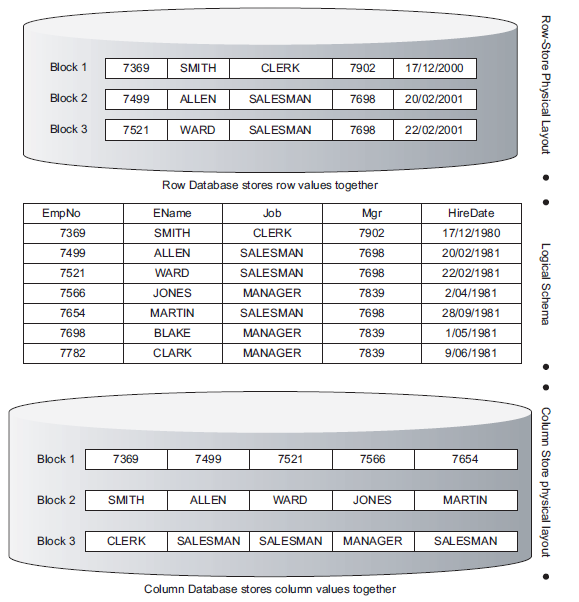 Column Database (C-store, Vertica) architecture
Column Database (C-store, Vertica) architecture
The big problem with column-oriented database is that DML is very expensive. A single row insert must update all of the blocks containing the columns for that row. In a columnar database, that multiples the write overhead dramatically.
Columnar compression in Oracle 11GR2
In 11g Release 2, Oracle has provided a compromise by introducing a form of columnar compression that works on top of normal row-oriented Oracle tables. Standard Oracle compression compresses the contents of a table row by row. This means that compression ratios will be higher if there is repeated data within a row. However, 11GR2 columnar compression compresses data on a column by column basis. This achieves much higher compression ratios, because there is likely to be more repeated data within a column than within a row. The drawback for columnar compression is that it takes a lot longer to create new data, since for each row inserted Oracle has to read all or some of the corresponding data values in other rows to see what data exists in other columns.
You can implement 11g R2 columnar compression using the “COMPRESS FOR ARCHIVE LEVEL=compression_level” syntax in the CREATE TABLE statement. Compression_level may take a value of 1,2 or 3. For instance I could create a compressed copy of the SALES table with the following statement:
CREATE TABLE sales_c
COMPRESS FOR ARCHIVE LEVEL=3 AS
SELECT *
FROM sh.sales s;
The higher the value of LEVEL, the better the compression but the higher the compression cost. DML times increase dramatically as you increase the LEVEL, but table scans times decrease. High values should generally be used for tables which are infrequently updated or where the speed of the update is not important.
The chart below illustrates the cost-benefit ratios for the various levels of compression. Higher levels of compression result in smaller segments which will be quicker to scan. However, the time taken to load the tables at the higher levels of compression are much greater. The appropriate level for your table will depend both on the usage patterns and the type of data – character data will compress better leading to more benefit. OLTP data will be updated more frequently leading to more overhead.
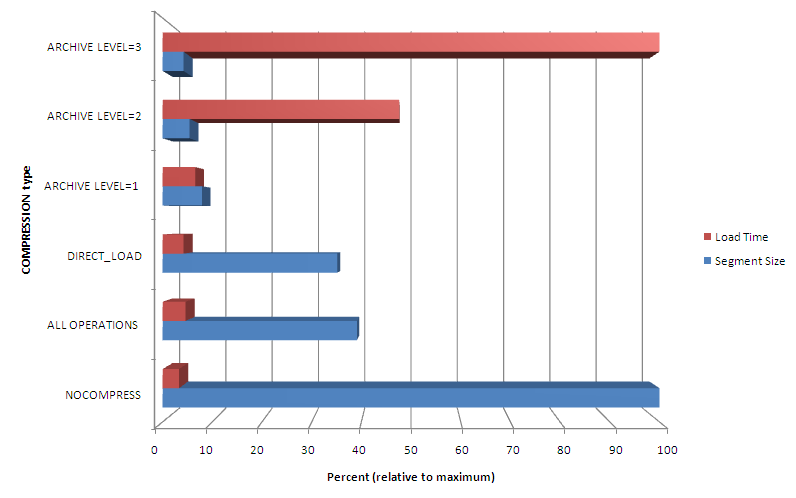
You can see that columnar compression results in much smaller segments sizes than the alternative compression options, but that the time to load the data increases correspondingly. If a table is relatively static, then using columnar compression would give some very significant improvements to full table scan performance.
There's more on compression - including 11gR2 columnar compression - and other new 11GR2 performance enhancements in my new book Oracle Performance Survival Guide. It's available for pre-order now, and should be in the stores by the end of the month.
Errata and apologies
I wrote the above based on research conducted during the 11GR2 beta program. In the production release there are two very important changes:
- Hybrid columnar compression is only available when using exadata storage.
- The syntax for specifying the compression levels has changed. Instead of "ARCHIVE LEVEL=n" the levels are (in order of increasing compression) "QUERY LOW", "QUERY HIGH" and "ARCHIVE".
I can't speak to Oracle's reasoning behind restricting columnar compression to exadata storage, though in a recent blog entry Kevin Closson says that it is for technical reasons. My testing during the beta program used conventional storage.
I promise in future to re-test always on the production release before posting :-(.



;) The print version is available for pre-order at Informit or Amazon and elsewhere, and is due in book stores on October 14th. There will be copies available at the Oracle Open World book store next week however and we'll be having a book signing with giveaways at the Quest Software booth, probably on Wednesday. I haven't seen a print copy myself yet, but I was probably the first to buy a digital copy :-). It will also soon be available on Kindle and on the Safari on-line bookshelf.
The print version is available for pre-order at Informit or Amazon and elsewhere, and is due in book stores on October 14th. There will be copies available at the Oracle Open World book store next week however and we'll be having a book signing with giveaways at the Quest Software booth, probably on Wednesday. I haven't seen a print copy myself yet, but I was probably the first to buy a digital copy :-). It will also soon be available on Kindle and on the Safari on-line bookshelf.  Guy Harrison
Guy Harrison