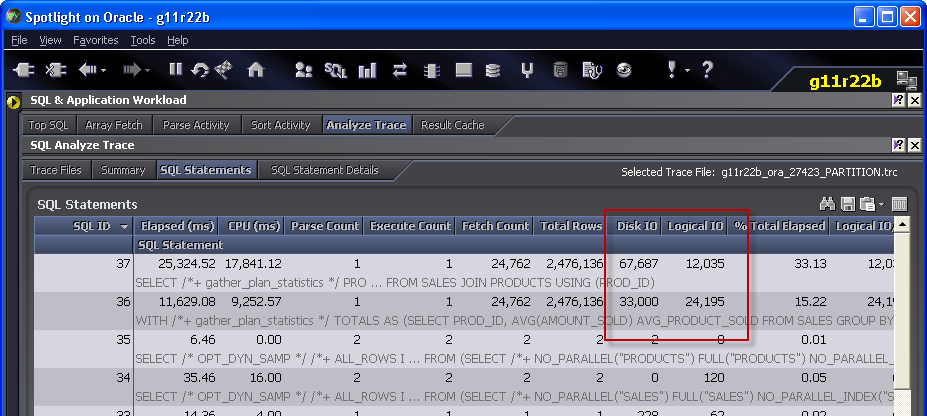
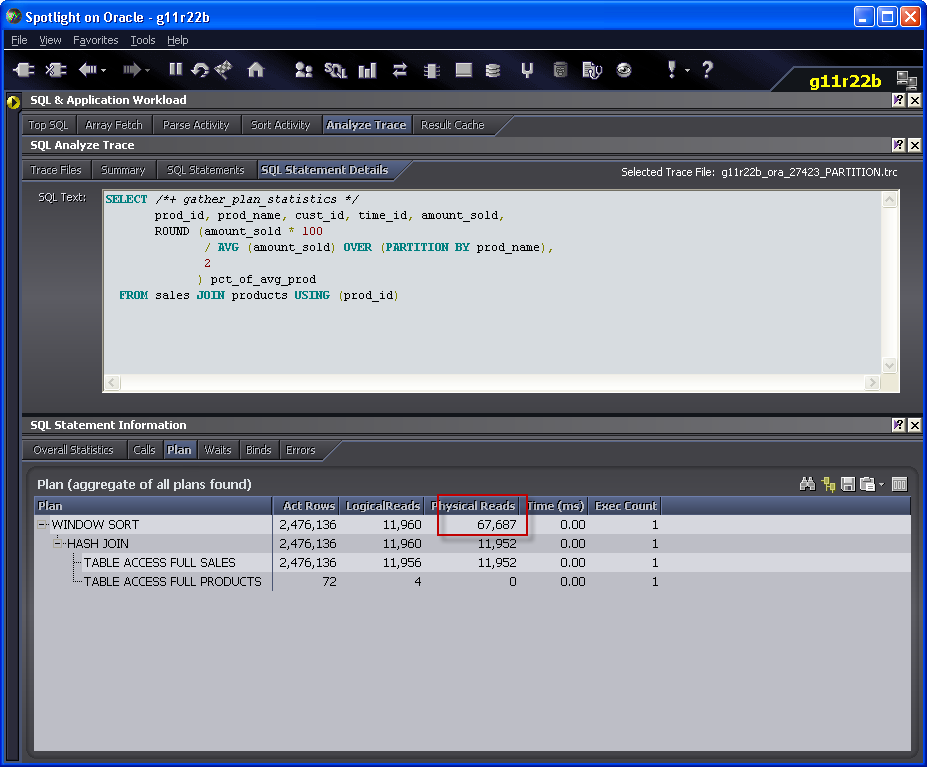
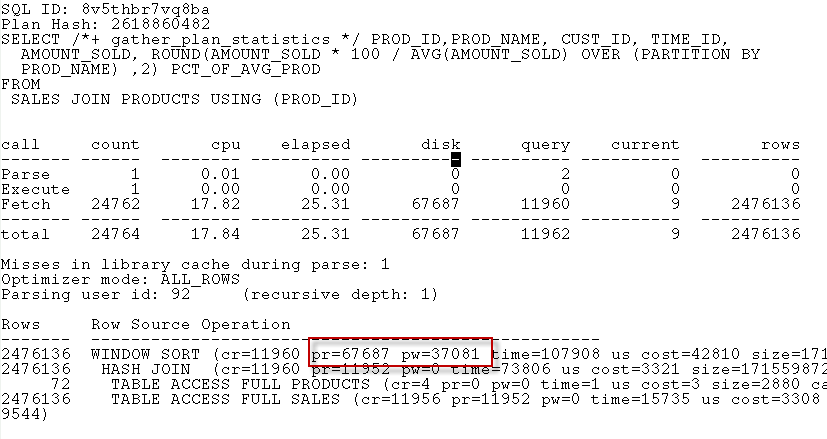
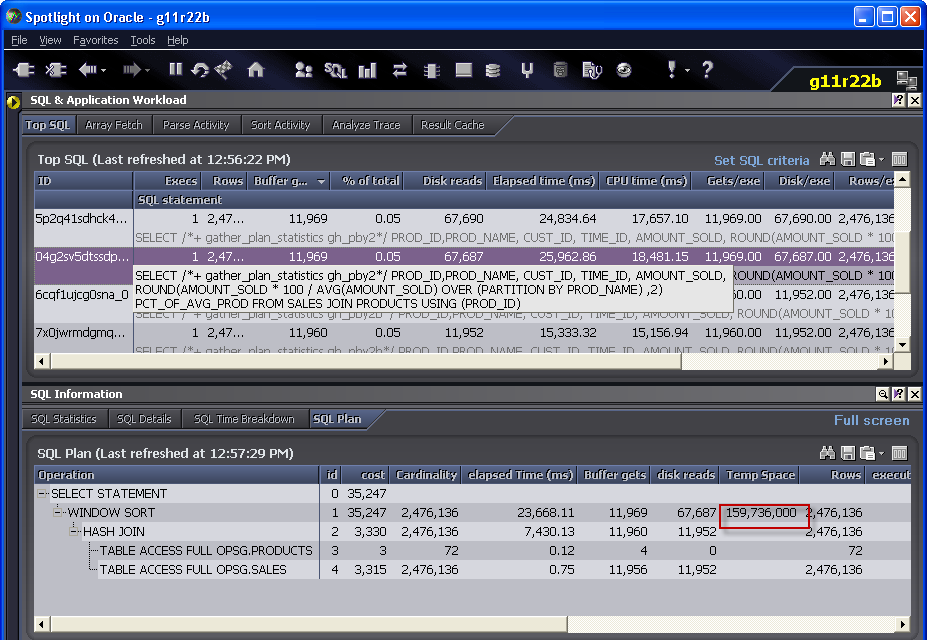
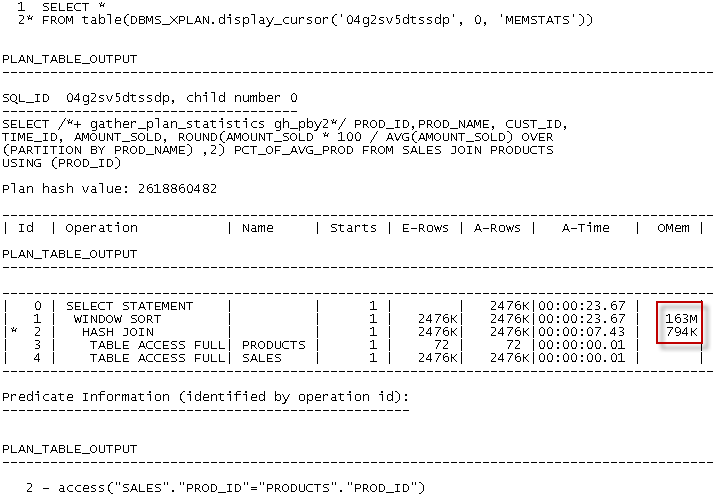
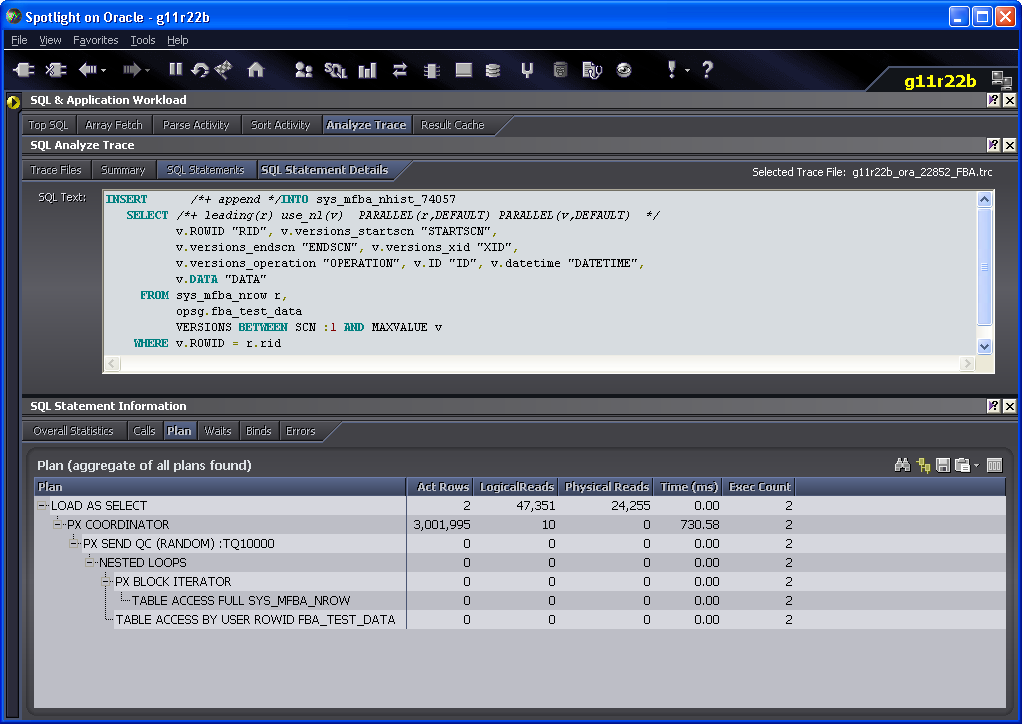
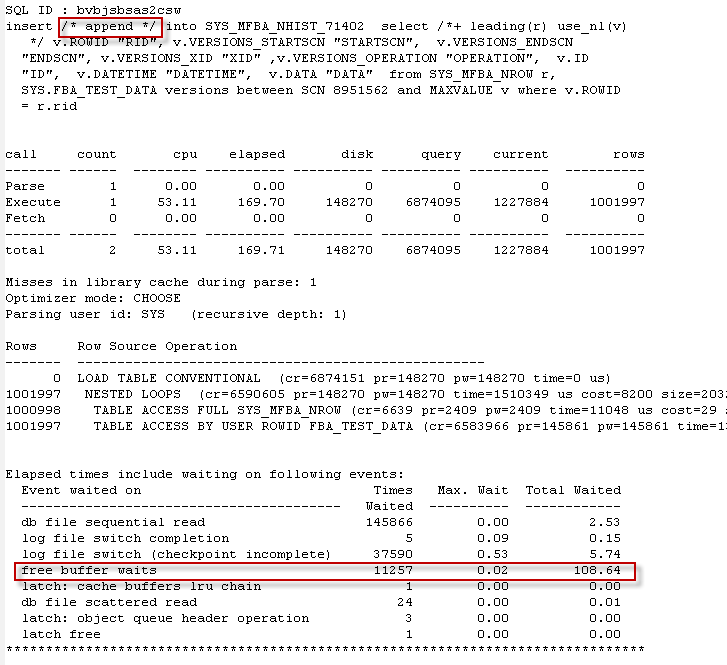
Joining V$PQ_TQSTAT to PLAN_TABLE output
When optimizing parallel execution, we have a couple oof sources of information, perhaps most importantly:
- The parallel execution plan as revealed by EXPLAIN PLAN and DBMS_XPLAN
- The data flows between each set of parallel processes as revealed by V$PQ_TQSTAT
The execution plan allows us to identify any serial bottlenecks in an otherwise parallelized plan, usually revealed by PARALLEL_FROM_SERIAL or S->P values in either the OTHER_TAG of the PLAN_TABLE or in the IN-OUT column of DBMS_XPLAN.
V$PQ_TQSTAT shows us the number of rows sent between each sets of parallel slaves. This helps determine if the work is being evenly divided between parallel slaves. Skew in the data can result in some slaves being over worked while others are underutilized. The result is that the query doesn’t scale well as parallel slaves are added.
Unfortunately, V$PQ_TQSTAT output is only visible from within the session which issued the parallel query and only for the most recent query executed. This limits its usefulness in a production environment, but it is still invaluable when tuning parallel queries.
It’s quite hard to correlate the output of DBMS_XPLAN and V$TQ_STAT so I wrote a script that tries to merge the output of both. It generates a plan for the last SQL executed by the session, and then joins that to the V$PQ_TQSTAT data. This is a little tricky, but I think the resulting script will generate useful output in a reasonably wide range of scenarios.
You can get the scrip here: tq_plan.sql. Your session will need access to the V$SQL_PLAN, V$SESSION and V$PQ_TQSTAT views.
Here’s some example output:
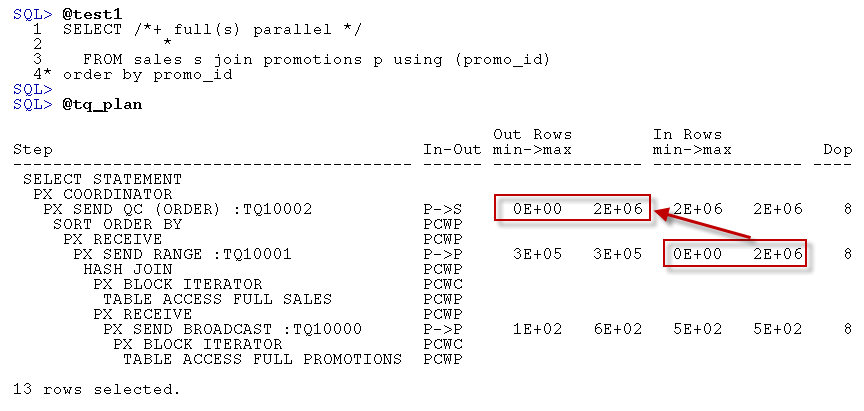
For each P->P, S->P or P->S step, the script shows the degree of parallelism employed ("Dop"), and the maximum and minimum rows processed by slaves. "Out Rows" represents the rows pushed from the first set of slaves, “In Rows” represents the number received by the next step. The highlighted portions of the above output reveal that this query is not parallelizing well: some slaves are processing 2 million rows, while others are processing none at all.
The reason this plan parallelizes so badly is that the PROMO_ID is such a skewed column. Almost all the PROMO_IDs are 999 ("No promotion") and so parallelizing the ORDER_BY PROMO_ID is doomed:
 When we parallelize an ORDER BY, we allocate rows for various value ranges of the ORDER BY column to specific slaves. For instance, in this diagram we see a parallelized ORDER BY on customer name; surnames from A-K are sent to one slave for sorting and surnames from L-Z sent to the other:
When we parallelize an ORDER BY, we allocate rows for various value ranges of the ORDER BY column to specific slaves. For instance, in this diagram we see a parallelized ORDER BY on customer name; surnames from A-K are sent to one slave for sorting and surnames from L-Z sent to the other:
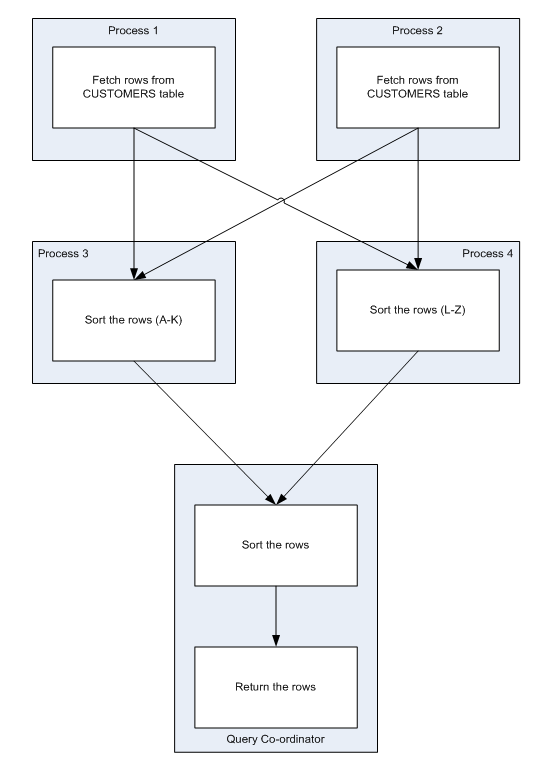
(This diagram is from Chapter 13 of Oracle Performance Survival Guide - ETA October 2009)
That approach works unless the rows are very skewed such as in our example - all 2 million of the "no promotion" rows go to a single slave which has to do virtually all of the work.
Anyway, the v$pq_tqstat view, despite it's limitations, is the best way to analyze this sort of skew. By linking the V$PQ_TQSTAT output to specific plan steps, hopefully my script will help you understand it's output.
 Guy Harrison
Guy Harrison