


Using flash disk for Redo on Exadata
In this Quest white paper and on my SSD blog here, I report on how using a FusionIO flash SSD compares with SAS disk for various configurations – datafile, flash cache, temp tablespace and redo log. Of all the options I found that using flash for redo was the least suitable, with virtually no performance benefit:
That being the case, I was surprised to see that Oracle had decided to place Redo logs on flash disk within the database appliance, and also that the latest release of the exadata storage cell software used flash disk to cache redo log writes (Greg Rahn explains it here). I asked around at OOW hoping someone could explain the thinking behind this, but generally I got very little insight.
I thought I better repeat my comparisons between spinning and solid state disk on our Exadata system here at Quest. Maybe the “super capacitor” backed 64M DRAM on each flash chip would provide enough buffering to improve performance. Or maybe I was just completely wrong in my previous tests (though I REALLY don’t think so :-/).
Our Exadata 1/4 rack has a 237GB disk group constructed on top of storage cell flash disk. I described how that is created in this post. I chose 96GB per storage cell in order to allow the software to isolate the grid disks created on flash to 4 24GB FMODs (each cell has 16 FMODs). Our Exadata system has fast SAS spinning disks – 12 per storage cell for a total of 36 disks. Both the SAS and SSD disk groups had normal redundancy.
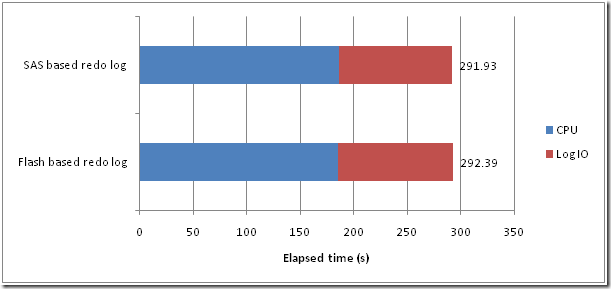
I ran an identical redo-intensive workload on the system using SAS or SSD diskgroups for the redo logs. Redo logs were 3 groups of 4GB per instance. I ran the workload on it’s own, and as10 separate concurrent sessions.
The results shocked me:

When running at a single level of concurrency, the SSD based ASM redo seemed to be around 4 times slower than the default SAS-based ASM redo. Things got substantially worse as I upped the level of concurrency with SSD being almost 20 times slower. Wow.
I had expected the SAS based redo to win – the SAS ASM disk group has 36 spindles to write to, while the SSD group is (probably) only writing to 12 FMODs. And we know that we don’t expect flash to be as good as SAS disks for sequential writes. But still, the performance delta is remarkable.
Conclusion
I’m yet to see any evidence that putting redo logs on SSD is a good idea, and I keep observing data from my own tests indicating that it is neutral at best and A Very Bad Idea at worse. Is anybody seeing any similar? Does anybody think there’s a valid scenario for flash-based redo?
 Guy Harrison
Guy Harrison
Reader Comments (13)
Can you describe your test a bit more and how you are collecting your metrics?
Any AWRs for this workload?
Will you be running it as well with the Exadata Smart Flash Logging?
Early days still with our new VMAX Symmetrix SAN - can't afford an Exadata, :-(
But so far all numbers I've seen confirm your claim, Guy.
I'm using 10gr2 and Statspack as well as AWR of late.
Both indicate an increase in redo waits when using SSD.
Hi Greg,
The workload is a tight loop of update/commit to a 1K column across a range of primary keys. Like this:
FOR i IN 1 .. p_rows LOOP
UPDATE txn_data_old
SET tdata = t_keylist (x)
WHERE txn_id = x + 300 * (p_job_no - 1);
COMMIT;
x := x + 1;
IF x > 200 THEN
x := 1;
END IF;
END LOOP;
After doing this for 500,000 rows (or whatever) it dumps v$session_event and v$sess_time_model to a log table which is used to generate the charts. We generally don't use AWR at Quest b/c we have to ensure that our products do not require features included in a pack. But the SQL at the end of this comment is what collects the data (with some added logic I can supply that performs delta calculations, etc).
I should have mentioned that we are at version 11.2.2.3.2 of the cellsrv software, so I think that means we are not using smart flash logging, right?
THanks, Guy
SELECT SYSDATE timestamp,
name,
total_waits,
time_waited_micro
FROM (SELECT n.wait_class,
e.event name,
e.total_waits,
e.time_waited_micro
FROM v$session_event e
JOIN
v$event_name n
ON (n.name = e.event)
WHERE n.wait_class <> 'Idle'
AND time_waited_micro > 0
AND sid = (SELECT DISTINCT sid FROM v$mystat)
UNION
SELECT stat_name,
stat_name,
NULL,
VALUE time_secs
FROM v$sess_time_model
WHERE stat_name IN ('DB CPU','DB time')
AND sid = (SELECT DISTINCT sid FROM v$mystat))
Correct Guy, 11.2.2.3.2 does not have the flash cache redo log feature. You would need the 11.2.2.4.0 image for that.
One thing to keep in mind: The new feature is a "best of both worlds", in that if the new feature is turned on, you will be writing to both spinning disks and flash cache. The latest release is intelligent, in that it will only wait for the first write to succeed, whether it be flash log or disk, and move on. I believe it's common knowledge that sequential write to SSD are generally considered poor, but for random writes, I've heard it performance is quite good. I haven't done my own tests on this yet, so if you get the 11.2.2.4.0 image, please do let us know how your testing goes.
--Rich
Hi Guy,
Did you happen to create the redo logs with the 11gR2 BLOCKSIZE parameter set to 4K? Flash does not like 512-byte multiple writes. That could be part of why it is so bad. That said, however, it is my experience that spinning disks are just fine for large sequential writes--naturally. I wouldn't expect that much difference with the new Smart Flash Log stuff either.
A white paper excerpt that supports Kevin's hypothesis:
"Only allocate files that perform I/Os on a 4 KB boundary alignment on the Sun Storage F5100
Flash Array. For the Oracle database this means Redo Logs should not be allocated on the Sun
Storage F5100 Flash Array. In this case Redo logs were allocated on the attached Sun Storage J4200
array from Oracle."
http://hosteddocs.ittoolbox.com/dce_us_en_wp_dramat21.pdf
Mike Wrote: "A white paper excerpt that supports Kevin's hypothesis:"
Mike,
My comment didn't reflect a hypothesis. The Sun F5100 and all other flash devices do much better with 4K multiple physical transfers. The whitepaper you reference must pre-date 11gR2 (when the BLOCKSIZE feature was introduced). The Sun F5100 will do just fine for redo with 4K BLOCKSIZE...but "fine" means don't expect much from redo on flash for the reasons I mention in my previous comment.
I had a shot at recreating the redo logs with a 4k blocksize but got a ORA-1378:
alter database add logfile thread 1 group 9 ('+DATA_SSD') size 4096M blocksize 4096
*
ERROR at line 1:
ORA-01378: The logical block size (4096) of file +DATA_SSD is not compatible with the disk sector size (media sector size is 512 and host sector size is 512)
In v$log the existing redo logs show up with a blocksize of 512, while the ASM diskgroup has a 4k blocksize. Is there a way to specify a sector size for the griddisk? I could not find a way to do that.....
Guy
Some devices (like the F20 card) do not report their block size correctly. You can override this by using
_disk_sector_size_override = TRUE
BTW, what version and patch level are you on? I looked though my notes and there was a fix put in for the F20 cards for this issue.
Greg,
Thanks for that advice, the "_disk_sector_size_overide" worked in allowing me to create the redo logs with the correct blocksize and performance improved dramatically. The SSD redo is now running about 30% slower than SAS based redo - it was at 480% slower so this is a massive improvement. I'll repeat the entire series and post updated results in the next few days.
I'm at cell releaseVersion 11.2.2.3.2. The DB is at 11.2.0.2.0.
Does the patch automatically use 4K block size for redo? I'm not the DB machine admin, and the machine is shared among a few of us at Quest, so I'll have to negotiate to get the versions upgraded. When that happens we'll probably go all the way to the latest version at which time I'd like to try out the redo flash cache feature.
Thanks again, Guy
I'm curious what the mode you used for archiving the redo logs and what the destination was. As Kevin points out, spinning rust does sequential writes just fine. When you add on re-reading the logs to write them somewhere else that changes things. If several SAS disk drives are reserved for just redo logs, then that seems like a lot of space used for just online redo logs to achieve a high uninterrupted sequential write rate. If the drives are not reserved for just redo, then applying various levels of query loads against tables and indexes sharing the drives in disk groups seems like a reasonable varying load to portray. Oracle keeps ignoring my hints that they should send me a box to play with, but I *suspect* that if the writes to the SAS drives for redo have to compete with other load and you are archiving your results will be reversed.
Maximizing the rate of redo file writes has never been my actual goal.
De-heating the rest of the disk farm has proven useful in every case I have tested, but I frankly was measuring the throughput of the overall job, not the total of redo write waits and redo write rate as a goal in isolation.
I doubt there will be controversy in stating that an exadata box is an inappropriate resource for your test's job mix, but I understand you were just attempting to generate a lot of redo, not portray a balanced workload.
It is true that I was always adding SSD (in the case of the first test, for Bechtel in 1993 real RAM based SSD), so I was removing that load from the spinning disk farm load. So maybe that is not a fair test if you can still add i/o capacity to the disk farm. That is, would the improvement I observed in throughput for the total job have been achieved or exceeded if there had in fact been additional i/o controllers available to add more spinning disks to the system for just redo logs? I doubt it but I just don't know.
I hope you have time to try a test where a heavy mixed workload is running in conjunction with a rapid change rate. Of course then the relevant metric will be total throughput, not redo write rate.
Regards,
Mark
I can support an all flash storage platform for databases. In our testing, PoCs and clients an all Flash solution works without issue. Prior to 11gR2, (_disk parameter is very helpful), you needed to be mindful of 4K alignment. Once that is in place unaligned IO can be managed..This is not unique to Flash, all advanced drive formats are 4K devices as well. In this case of violin we do not see this issue with Redo as long we are making sure that we are aligned on a 4K boundary.
A another nice feature with 11gR2 and the 2.6.32 Linux Kernel is native support for 4K sector devices (no specific need to use the _disk parameter).
Don't forget when setting this parameter you can also specify sector size for the ASM disk groups as well.
Ping me sometime an we can catch up on flash and the database world.