


Amazon Elastic Map Reduce (EMR), Hive, and TOAD
Since my first post on connecting to Amazon Elastic Map Reduce with TOAD, we’ve added quite a few features to our Hadoop support in general and our EMR support specifically, so I thought I’d summarize those features in this blog post
Amazon Elastic Map Reduce is a cloud-based version of Hadoop hosted on Amazon Elastic Compute Cloud (EC2) instance. Using EMR, you can quickly establish a cloud based Hadoop cluster to perform map reduce work flows.
EMR support Hive of course, and Toad for Cloud Databases (TCD) includes Hive support, so let’s look at using that to query EMR data.
Using the Toad direct Hive client
TCD direct Hive connection support is the quickest way to establish a connection to Hive. It uses a bundled JDBC driver to establish the connection.
Below we create a new connection to a Hive server running on EMR:

- Right click on Hive connections and choose “Connect to Hive” to create a new Hive connection.
- The host address is the “Master” EC2 instance for your EMR cluster. You’ll find that on the EMR Job flow management page within your Amazon AWS console. The Hive 0.5 server is running on port 10000 by default.
- Specifying a job tracker port allows us to track the execution of our Hive jobs in EMR. The standard Hadoop jobtracker port is 50030, but in EMR it’s 9600.
- It’s possible to open up port 10000 so you can directly connect with Hive clients, but it’s a bad idea usually. Hive has negligible built-in security, so you’d be exposing your Hive data. For that reason we support a SSH mode in which you can tunnel through to your hadoop server using the keypair file that you used to start the EMR job flow. The key name is also shown in the EMR console page, though obviously you’ll need to have an actual keypair file.
The direct Hive client allows you to execute any legal Hive QL commands. In the example below, we create a new Hive table based on data held in an S3 bucket (The data is some UN data on homicide rates I uploaded).

Connecting Hive to the Toad data hub
It’s great to be able to use Hive to exploit Map Reduce using familiar (to me) SQL-like syntax. But the real advantage of TCD for Hive is that we link to data that might be held in other sources – like Oracle, Cassandra, SQL Server, MongoDB, etc.
Setting up a hub connection to EMR hive is very similar to setting up a direct connection. Of course you need a data hub installed (see here for instructions), then right click on the hub node and select “map data source”:
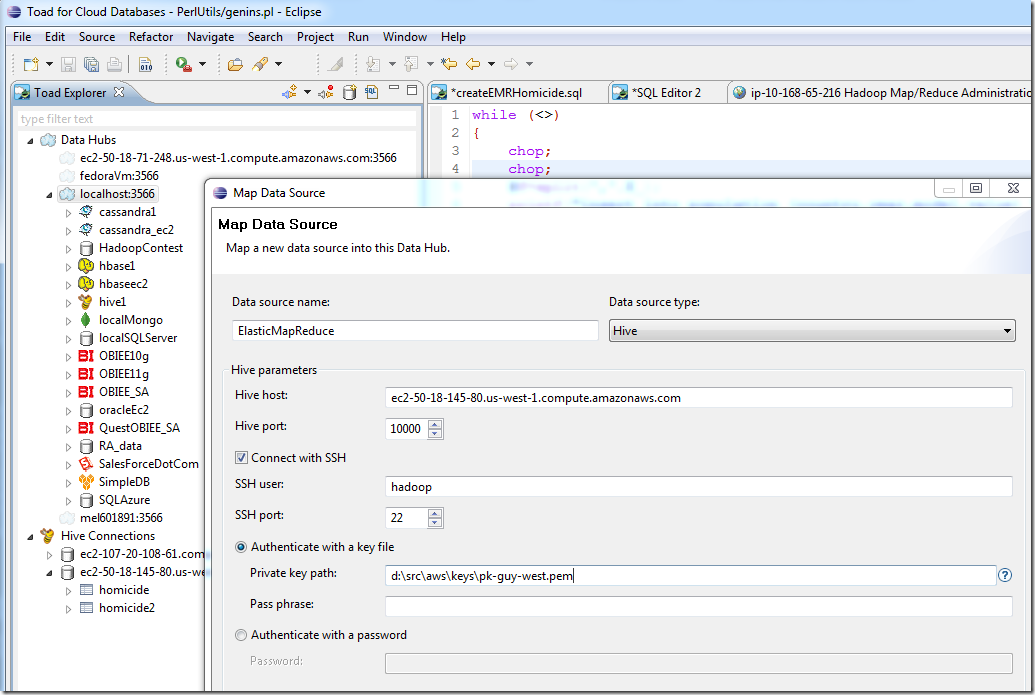
Now that the hub knows about the EMR hive connection, we can issue queries that access Hive and – in the same SQL – other datasources. For instance, here’s a query that joins homicide data in Hive Elastic Map Reduce with population data stored in a Oracle database (running as Amazonn RDS: Relational Database Service). We can do these cross platform joins across a lot of different types of database sources, including any ODBC compliant databases, any Apache Hbase or Hive connections, Cassandra, MongoDB, SimpleDB, Azure table services:
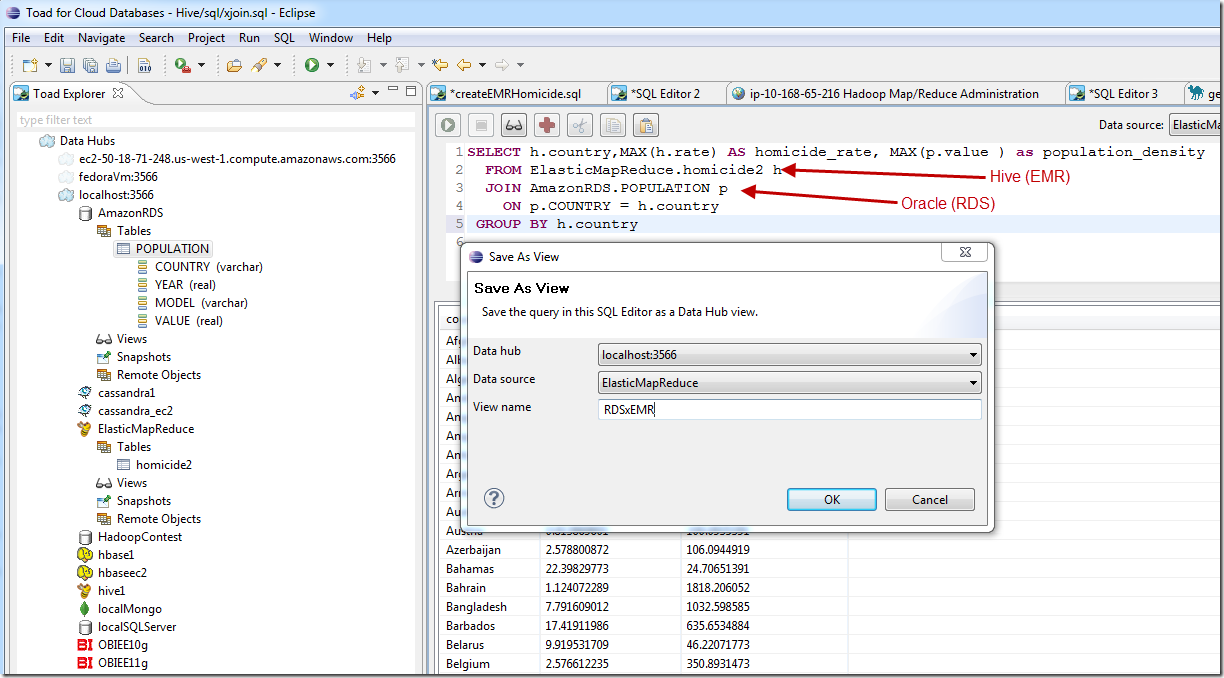
In the version that we are just about to release, queries can be saved as views or snapshots, allowing easier access from external tools of for users who aren’t familiar with SQL. In the example above, I’m saving my query as a view.
Using other hub-enabled clients
TCD isn’t the only product that can issue hub queries. In beta today, the Quest Business Intelligence Studio can attach to the data hub, and allows you to graphically explore you data using drag and drop, click and drilldown paradigms:
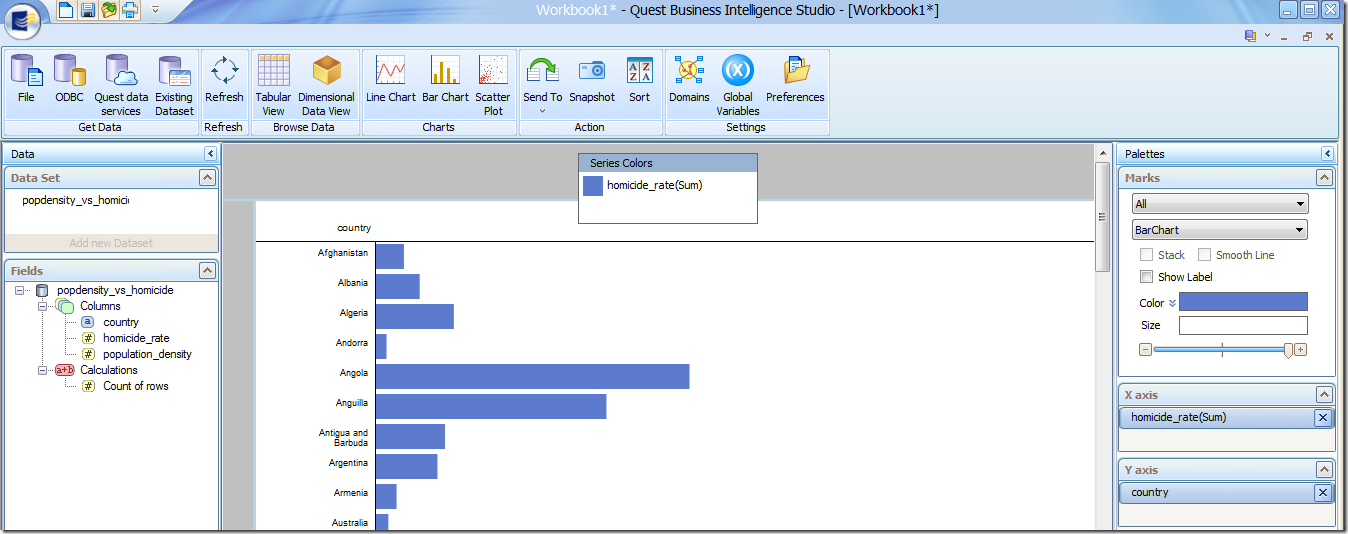
It’s great to be living in Australia – one of the lowest homicide rates!
If you’re a hard core data scientist, you can even attach R through to the hub via the RODBC interface. So for instance, in the screen shot below, I’m using R to investigate the correlation between population density and homicide rate. The data comes from Hive (EMR) and Oracle (RDS), is joined in the hub, saved as a snapshot and then feed into R for analysis. Pretty cool for a crusty old stats guy like me (My very first computer program was written in 1979 on SPSS).

 TCD blog post
TCD blog post
Reader Comments