Getting started with Apache Pig
If, like me, you want to play around with data in a Hadoop cluster without having to write hundreds or thousands of lines of Java MapReduce code, you most likely will use either Hive (using the Hive Query Language HQL) or Pig.
Hive is a SQL-like language which compiles to Java map-reduce code, while Pig is a data flow language which allows you to specify your map-reduce data pipelines using high level abstractions.
The way I like to think of it is that writing Java MapReduce is like programming in assembler: you need to manually construct every low level operation you want to perform. Hive allows people familiar with SQL to extract data from Hadoop with ease and – like SQL – you specify the data you want without having to worry too much about the way in which it is retrieved. Writing a Pig script is like writing a SQL execution plan: you specify the exact sequence of operations you want to undertake when retrieving the data. Pig also allows you to specify more complex data flows than is possible using HQL alone.
As a crusty old RDBMS guy, I at first thought that Hive and HQL was the most attractive solution and I still think Hive is critical to enterprise adoption of Hadoop since it opens up Hadoop to the world of enterprise Business Intelligence. But Pig really appeals to me as someone who has spent so much time tuning SQL. The Hive optimizer is currently at the level of early rule-based RDBMS optimizers from the early 90s. It will get better and get better quickly, but given the massive size of most Hadoop clusters, the cost of a poorly optimized HQL statement is really high. Explicitly specifying the execution plan in Pig arguably gives the programmer more control and lessens the likelihood of the “HQL statement from Hell” brining a cluster to it’s knees.
So I’ve started learning Pig, using the familiar (to me) Oracle sample schema which I downloaded using SQOOP. (Hint: Pig likes tab separated files, so use the --fields-terminated-by '\t' flag in your SQOOP job).
Here’s a diagram I created showing how some of the more familiar HQL idioms are implemented in Pig:
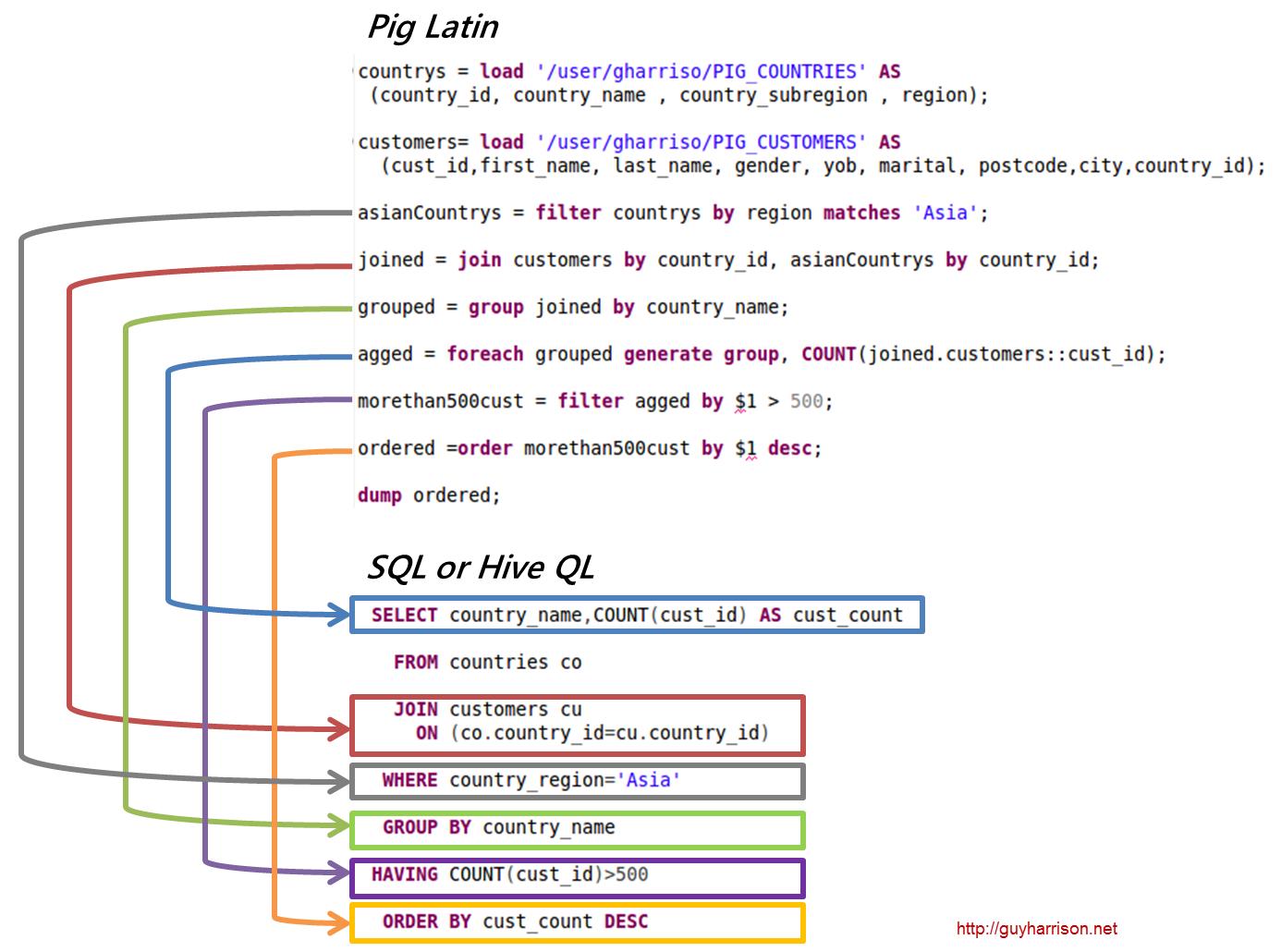
Note how using Pig we explicitly control the execution plan: In HQL it’s up to the optimizer whether tables are joined before or after the “country_region=’Asia’” filter is applied. In Pig I explicitly execute the filter before the join. It turns out that the Hive optimizer does the same thing, but for complex data flows being able to explicitly control the sequence of events can be an advantage.
Pig is only a little more wordy than HQL and while I definitely like the familiar syntax of HQL I really like the additional control of Pig.
 TCD blog post
TCD blog post