Using hints with join methods
Jonathan Lewis often says that hints are generally inadvisable for production systems, and - with some reservations - I agree. The most significant problem with hints is that they can go disastrously wrong when schema or other changes to the database occur. They can also prevent the optimizer from exploiting possible improvements that might otherwise be obtained when new indexes or other changes are made. If you use hints, you are increasing the amount of care you need to take when making schema changes - especially when changing indexing.
Despite that warning, hints clearly do have a place when all else fails, and are definitely useful in test environments to compare the costs of various plan options. In Spotlight on Oracle, we issue SQL that has very stringent performance requirements against tables (X$ views usually) where we are unable to create histograms and where most other optimization methods are unavailable. Consequently we fairly routinely hint our production SQL. We might be special case , but the world is made up of special cases!
In this post I want to provide an example of where a simple hint can go disastrously wrong, and yet at the same time be the only practical way of achieving a certain plan.
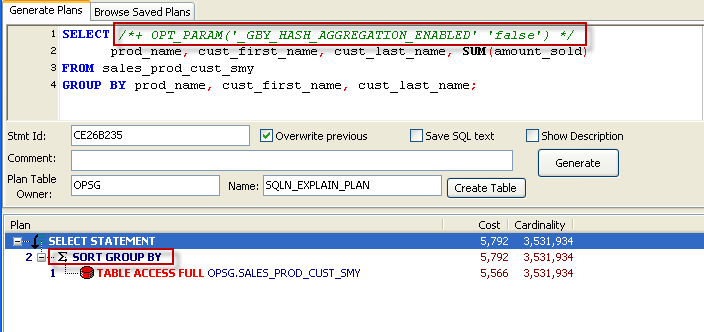
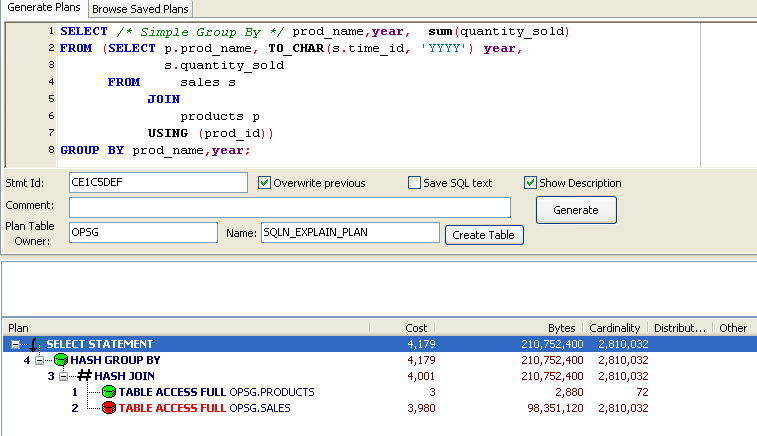
Consider the following SQL:

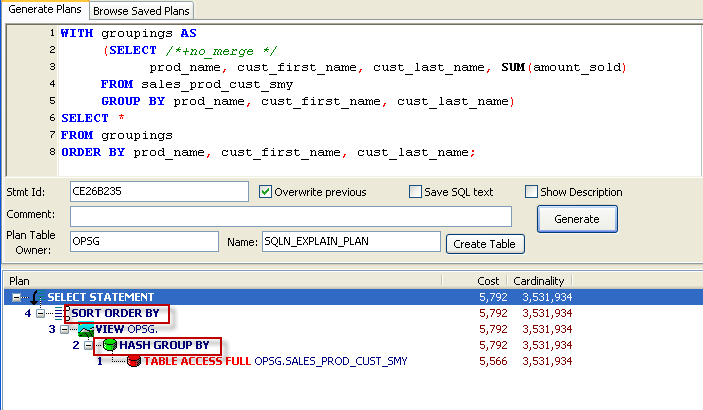
One circumstance in which you might be tempted to use a hint is when you want to specify a join method. We know that New Zealand - while very lovely - isn't the home of many of our customers and so we probably want to use an indexed based lookup to get their sales data. However, when we examine the execution plan we see that the optimizer has chosen a hash join and a full table scan of SALES:
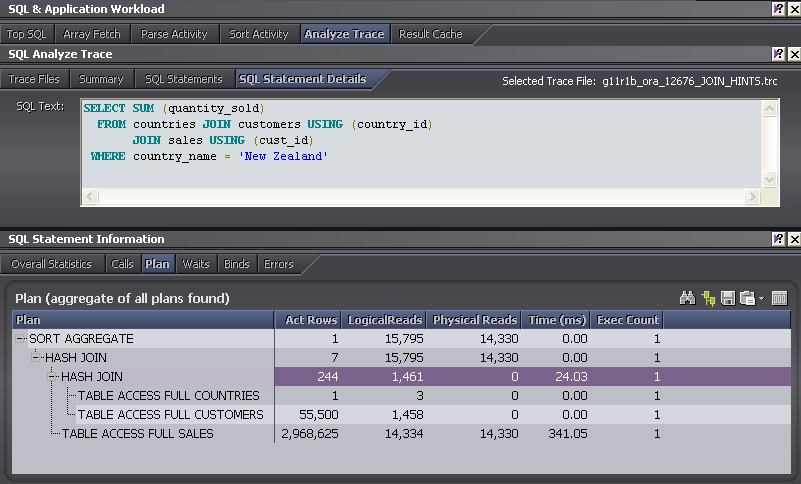
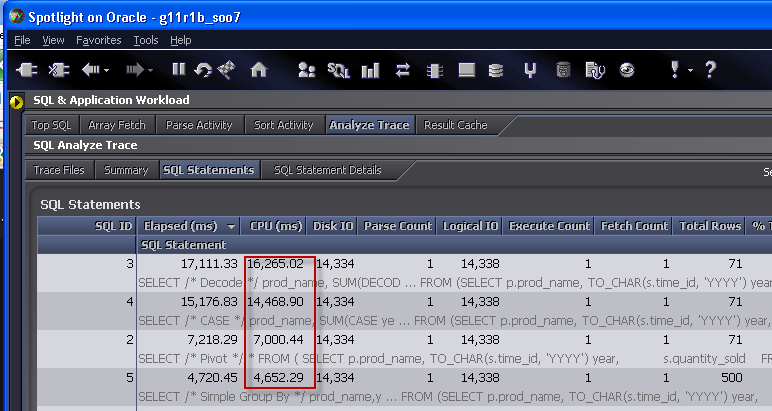
(The output above is from Spotlight on Oracle's Analyze trace facility - tkprof would show much the same output)
It's easy enough to use a set of hints to get the plan we want. The USE_NL hint specifies that nested loops should be used for a join, and so here we use it - and a few other hints - to get the join we want:
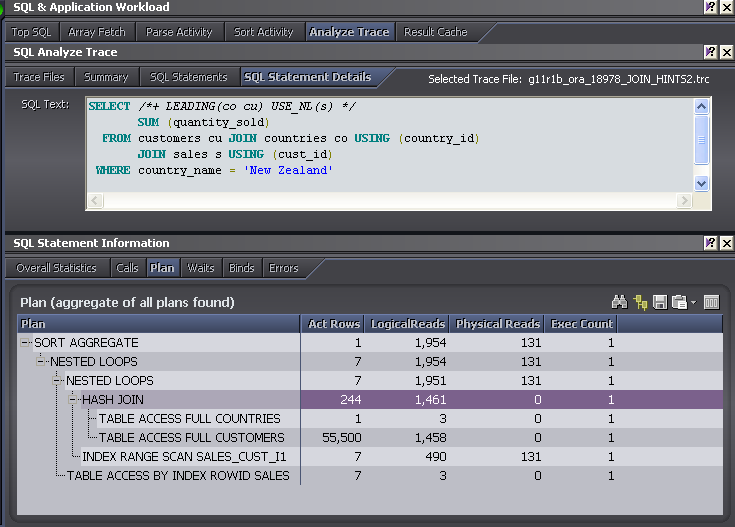
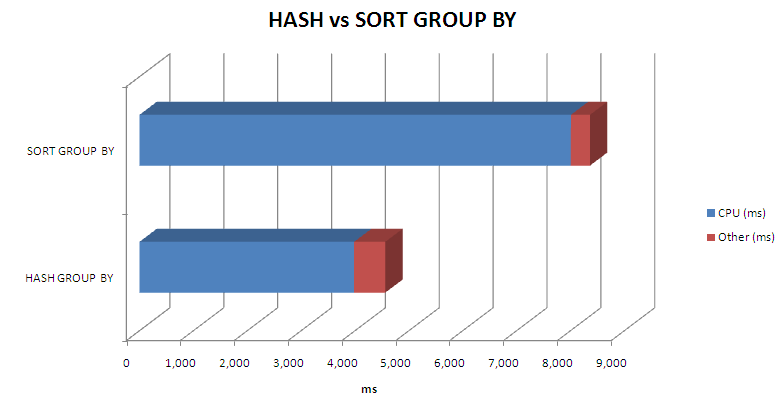
We get a good reduction in elapsed time (1,000ms->44ms) and logical reads (15,795 -> 1,954), and so this might be considered a successful outcome. The use of the index based plan reduces physical IO as well, since 11g is using direct reads for the full table scans and so is getting no advantage out of the buffer cache.
However, we've also created a large vulnerability. If the index on which the nested loops join is based is ever dropped, or changed in such a way to be unable to support the join, then Oracle will continue to obey the USE_NL hint even though the result will now be a nested table scan. Here's the plan when the index is dropped:
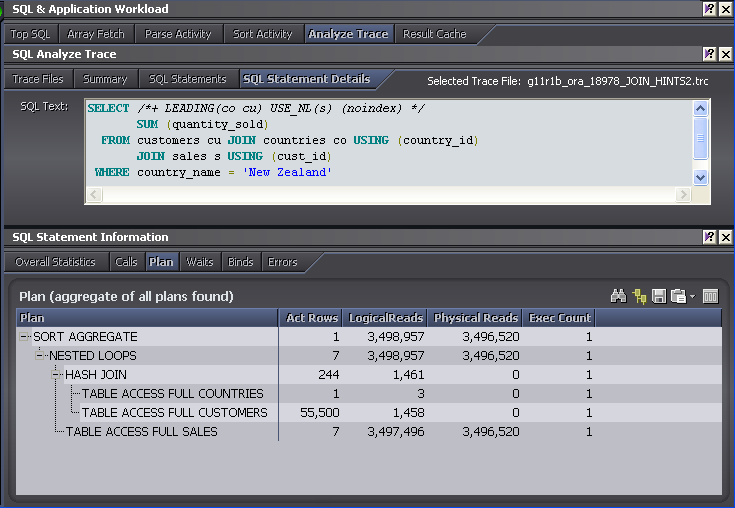
Truly disastrous! We are now performing a full table scan of SALES for every matching customer. The logical reads are now almost 3.5 million, and elapsed time rises to over 80s - 80 times worse than without the hint.
The USE_NL_WITH_INDEX hint
The USE_NL hint has caused enough problems of this type for Oracle to introduce a "safer" alternative: USE_NL_WITH_INDEX. This works the same as USE_NL but only if there's an index available to support the nested loops. USE_NL_WITH_INDEX will not result in the nested table scans plan we see above, if the index is not available it falls back to the hash join:
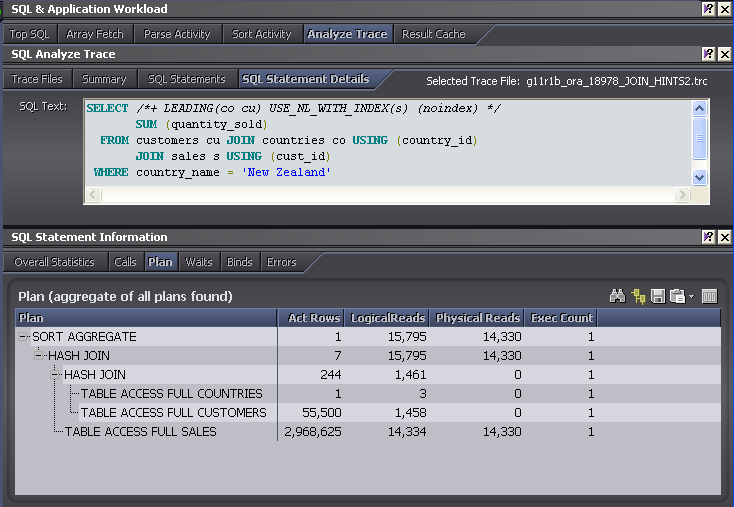
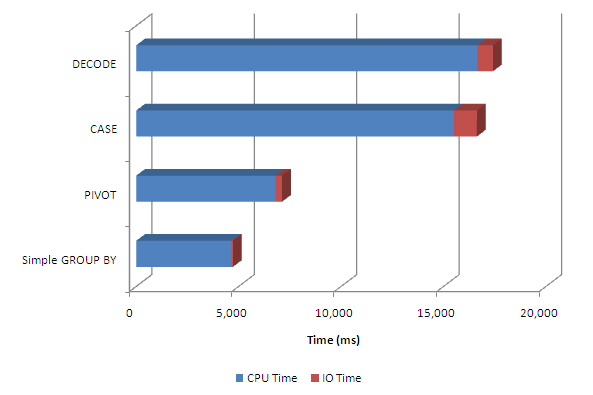
So here's the comparison of the two hints compared with the default plan:
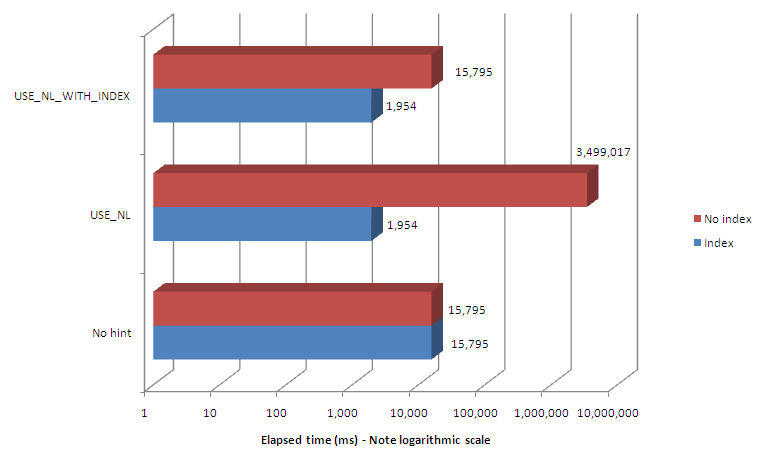
The USE_NL_WITH_INDEX hint is generally preferable to the USE_NL hint because it should never result in nested table scans.
Alternatives to hinting
When I started writing this, I thought the moral of the story was going to be to collect histograms on skewed columns. Surely, if I created a histogram on all the join columns, the optimizer would work out that there weren't many New Zealand customers and choose nested loops on it's own, right?
Wrong. Even with wide histograms on all columns with 100% estimates, Oracle always chose the hash join.
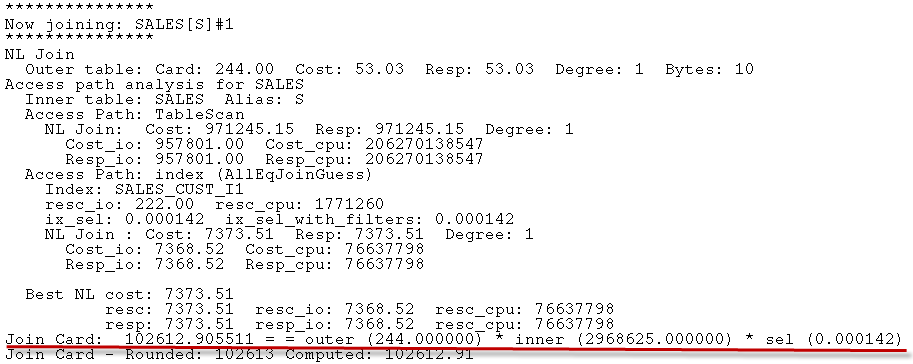
Using the 10053 trace event, we can see some of the optimizer's thinking and see why the better plan was not chosen. Here, we see the optimizer calculating the cost for a Nested Loops join between CUSTOMERS and SALES. The key calculation is underlined in red:
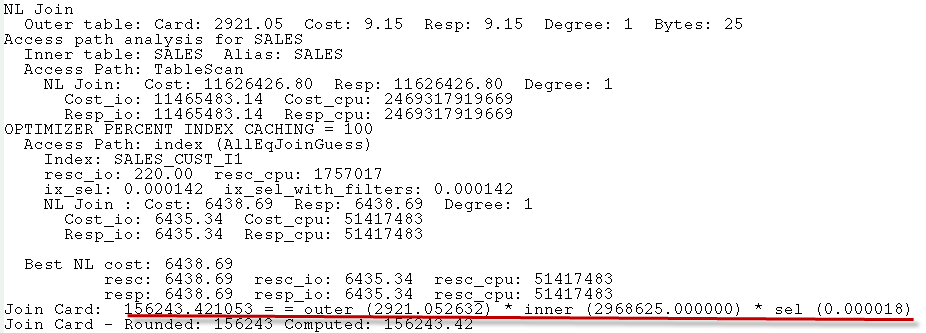
The join cardinality is based on an expected 2,921 rows returned from the outer table - CUSTOMERS - and an index selectivity of .000018. In fact, there are only 244 customers from New Zealand - 2921 is the average number of customers across all countries. From that initial miscalculation, the failure to choose the nested loops join is inevitable. I thought that histograms on CUSTOMERS.COUNTRY_ID and SALES.CUST_ID might have allowed Oracle to calculate the cardinality correctly. Sadly not.
Upon reflection, I realized that while the optimizer can work out that the 'New Zealand' row in COUNTRIES returns only one row, it cannot- without actually executing the statement - work out how many matching rows exist in the CUSTOMERS table. If we provide the COUNTRY_CODE directly as in this statement:

Then we can see in the 10053 trace that the cardinality is correctly determined. The calculation below - that there will be 244 customer rows returned - is correct:
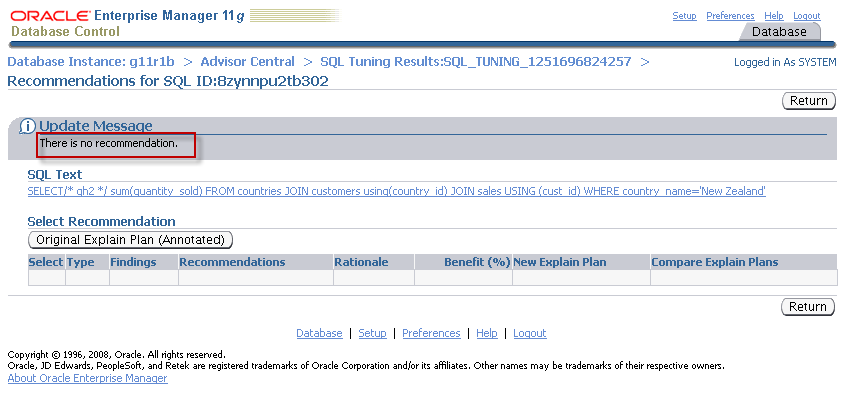
SQL Tuning advisor to the rescue? (No)
In theory, the SQL tuning advisor ought to be able to compare the actual rows output from each step during execution and then adjust the estimated rows accordingly. I therefore had high hopes that running the advisor on my statement would give me the result I wanted. However, it really was not my day. The SQL tuning advisor was unable to provide an alternative plan either:
Changing the optimizers assumptions
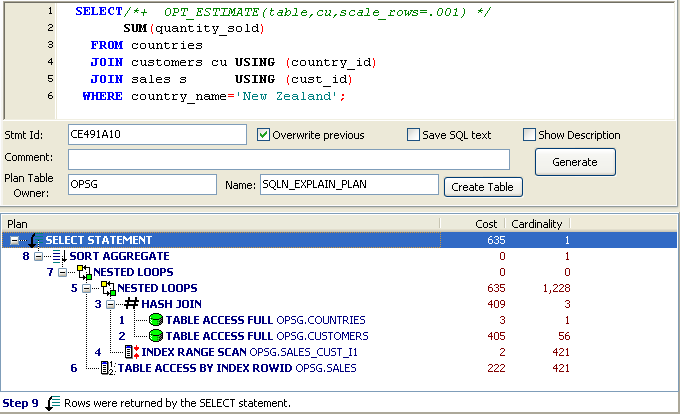
Maybe we would be best off changing the optimizers assumptions... Since it's the failed cardinality that is at the root of the problem, let's try to adjust that. OPT_ESTIMATE is the undocumented hint that SQL profiles use to adjust the plan. We can use it to adjust the expected cardinality of the CUSTOMERS lookup by .001. This will reduce the number of rows expected to be returned by 1/100th.
And it works: we get the index based nested loops:
Is this better than the USE_NL_WITH_INDEX hint? Possibly, though things could go wrong if the data volumes and distributions change. What I really want is to be able to collect a "join histogram" that will allow Oracle to determine the number of rows returned from CUSTOMERS when joined to the New Zealand COUNTRIES row. I can't think of an obvious and simple way to do that; we can only hope that future versions of DBMS_SQLTUNE (the SQL tuning advisor) can correct join issues like this.
Conclusion
Hints in production code should definitely be used with care. We've seen an example above where a hint can result in massive SQL degradation when indexing changes. Some hints are "safer" than others - USE_NL_WITH_INDEX is better than USE_NL for instance.
It can sometimes be surprisingly hard, however, to get Oracle to do the right thing. In a perfect world we should be able to get the plan we want through accurate and comprehensive statistics or - if that fails - by running the SQL access advisor and creating a profile. Alas, it still seems that even for fairly simple cases - involving joins in particular - the optimizer will fail to determine the correct path. In those cases, hints seem to be the only option if we want to get the most efficient path.
 Guy Harrison
Guy Harrison