More on the database flash cache
I'm eagerly awaiting my high-performance flash SSD (an Intel X-25 E), but in the meantime I've played a bit more with the database flash cache on the cheap hardware setup described in my last post. Sometimes it can be useful to test new features on slow hardware, since you observe phenomenon that don't occur when everything is running full speed.
I originally naively imagined that blocks would be copied into the flash cache by the Oracle server process . Eg, that if I read from disk, I deposit the block in both the buffer cache or the flash cache. However, upon investigation it appears that blocks are moved from the buffer cache to the flash cache by the DBWR as they are about to be flushed from the buffer cache.
This is of course, a much better approach. The DBWR can write to the flash cache asynchronously, so that user sessions get the benefit - less time reading from magnetic disk - without having to wait while blocks are inserted into the flash cache.
So the lifecycle of a block looks something like this:
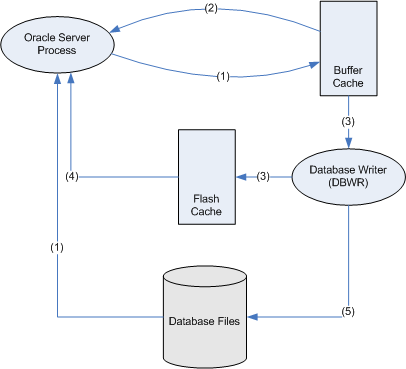
- The Oracle server process reads a file from disk and adds it to the buffer cache
- If a session wants that block later and it's still in the buffer cache, they can read it from the buffer cache
- Before the block leaves the buffer cache the DBWR will write it to the flash cache (if the DBWR is not too busy)
- If a session want a block later and it's still in the flash cache, then they will read it from the flash cache (and presumably place it back in the buffer cache)
- If the block is modified, the DBWR will eventually write it back to the disk. (Q: What happens to any unmodified copies of that block in the flash cache?)
DBWR and the flash cache
Reading from flash is fast - but writing is much slower. Therefore, in order to avoid performance issues, the DBWR should:
- Not write to flash unless it has to and
- Not write to flash at all if it will get in the way of other more important activities.
To the first point, DBWR does not appear to populate the flash cache until blocks are about to be flushed. In other words, the DBWR doesn't seem to write a buffer to the flash cache just in case it is going to be flushed, but only if it is actually (or maybe probably) going to be flushed. We do not observe writes to the flash cache when blocks are brought into the buffer cache unless other blocks are also being flushed out.
Secondly, the DBWR won't write to flash cache - and won't delay blocks from being flushed - if it is busy writing dirty blocks to disk. The DBWR must clear dirty blocks from the cache as quickly as possible, otherwise "free buffer waits" will prevent new blocks from being introduced to the buffer cache. If blocks are about to be flushed from the buffer cache but the DBWR is busy then the blocks will not get written to the flash cache, and the statistic 'flash cache insert skip: DBWR overloaded' will be incremented.
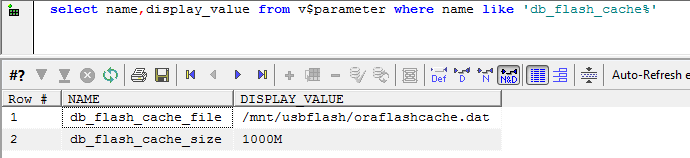
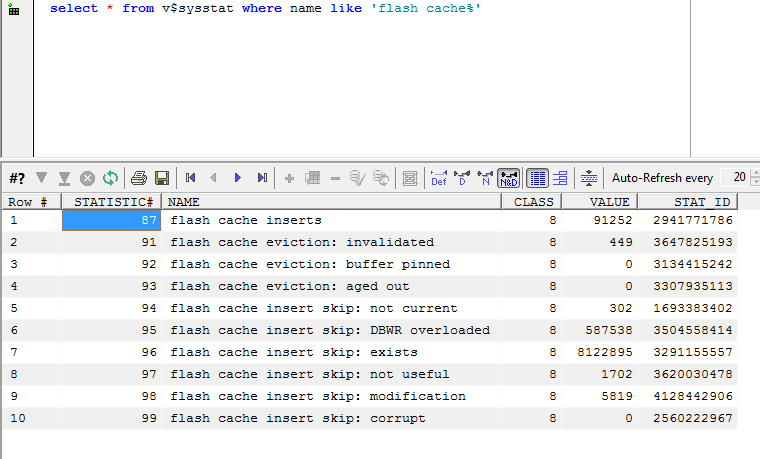
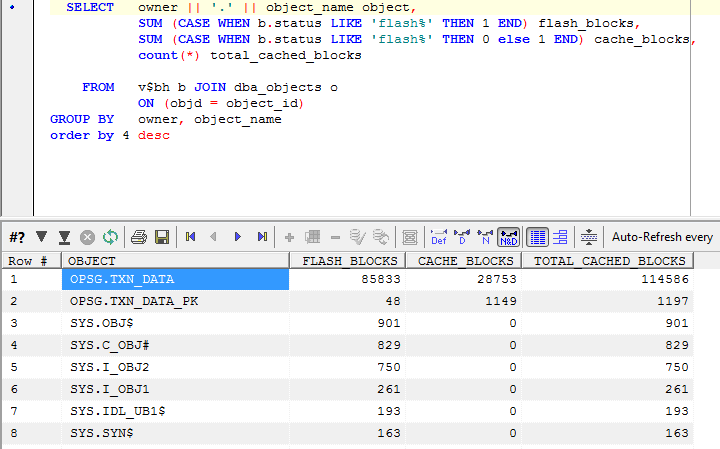
Measuring db flash cache effectiveness
The following query reports on how often a busy DBWR is forced to skip flash cache inserts because it is too busy or for other reasons:
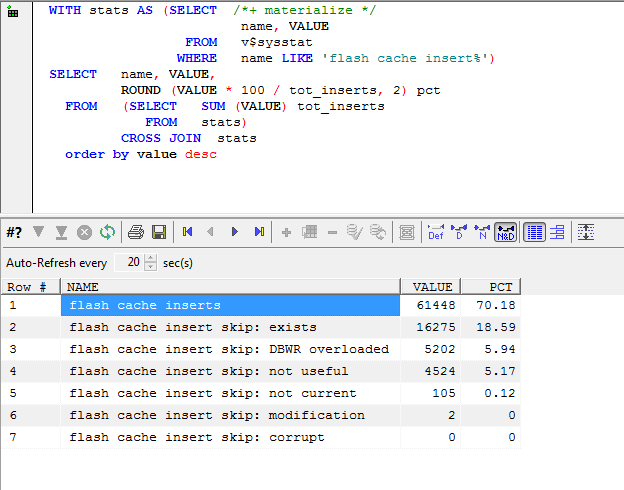
The "DBWR overloaded" statistic I think we understand - the DBWR is busy writing dirty blocks to disk and hasn't the bandwidth to write clean blocks to the flash cache.
"flash cache insert skip: exists" is also easy to understand. If we read a block back from the flash cache into the buffer cache, then it remains in the flash cache. There's no need to write it to the flash cache again should it again age out of the buffer cache.
"not current" probably means that the DBWR is aware of a more recent copy of the block on disk or in the buffer cache and for that reason is going to decline to write a version to flash.
"not useful" I do not understand....
The biggest takeaway here is - I think:
On a system with a very busy DBWR, the db flash cache may be less effective.
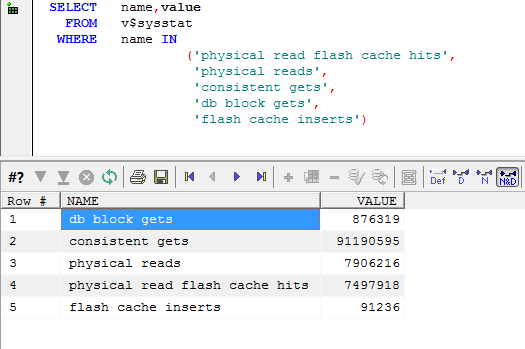
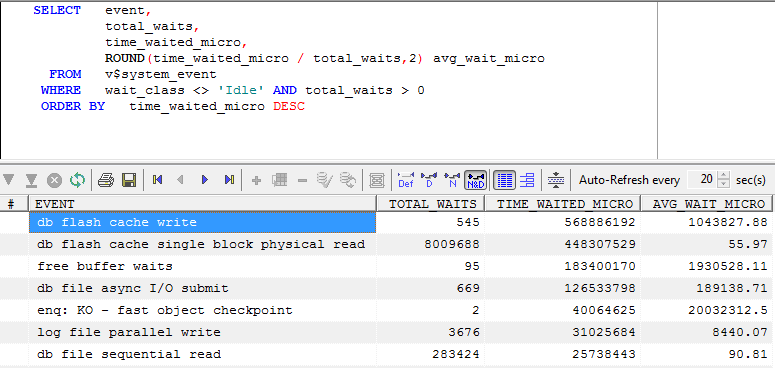
To measure the benefit from the flash cache we can compute the number of flash cache reads that avoided a physical read and multiply by the average time for each type of read. This query attepts to do that though only for single block reads:
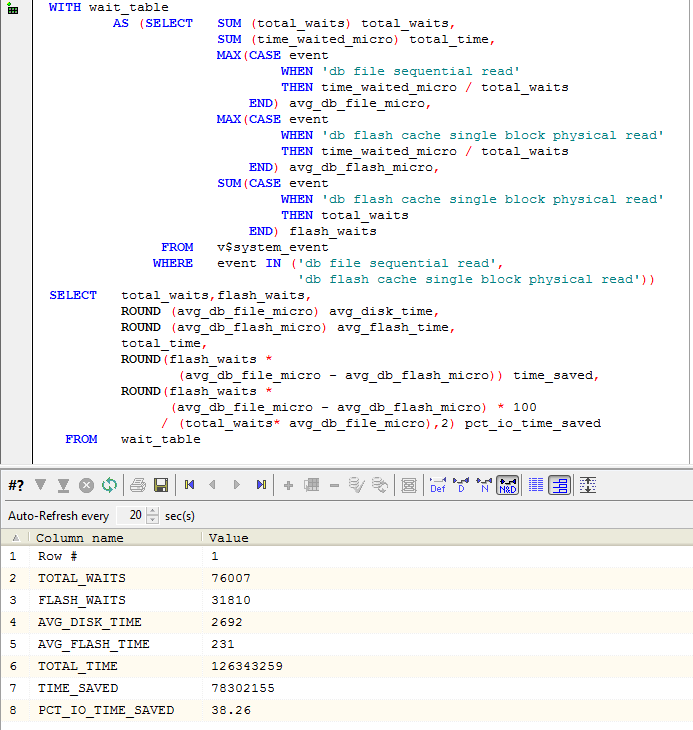
Conclusion
The architecture of the DB flash cache allows us to relax a bit regarding the relatively poor write performance that is associated with flash SSD. If we place a datafile on flash SSD, we risk creating a free buffer wait bottleneck: the DBWR will stall trying to write blocks to the slow (in terms of write latency) flash drive and so we might actually get worst performance compared to magnetic disk - at least if we have a high write rate. But with the flash cache, the DBWR only writes when it has free time. Consequentially, there should be little real down side - the worst that can happen is that the DBWR is too busy to populate the flash cache and so it becomes less useful.
The efficiency of the db flash cache is going to depend on two main factors:
- Does the DBWR have enough free time to write to the flash cache?
- How long does it take to write to the flash device?
The answer to the first question depends on the current rate of DBWR activity which in turn probably depends on how much IO write bandwidth exists on your disk array. But if you have the sort of database that suffers from or is on the verge of suffering from free buffer waits, then probably the db flash cache won't work too well because the DBWR will never be able to write to it.
The answer to the second question depends on the quality of the flash SSD. You generally want to use Flash disks which have the lowest possible write latency. That usually means support for the TRIM API call, and flash that uses Single Level Cells (SLC).
 Guy Harrison
Guy Harrison