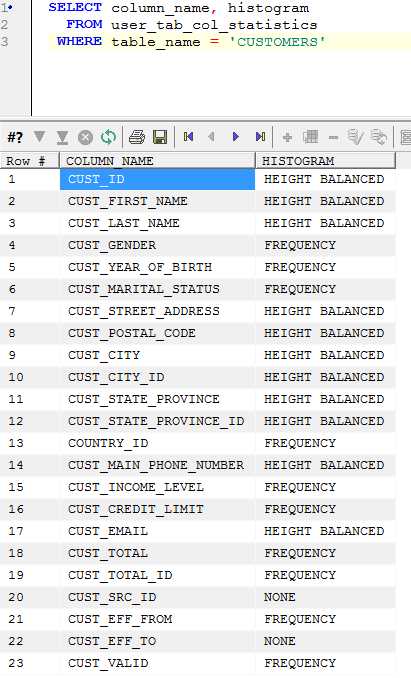
Memory Management for Oracle databases on VMWare ESX
The trend towards virtualization of mid-level computing workloads is progressing rapidly. The economic advantages of server consolidation and the – often exaggerated – reduction in administration overheads seem pretty compelling. And virtualized servers are quicker to provision and offer significant advantages in terms of backup, duplication and migration.
The virtualization of Oracle databases has proceeded more slowly, due to concerns about performance, scalability and support. Oracle corporation has given mixed messages about support for virtualized databases, though they currently appear to have conceded that Oracle databases on VMWare are supported, at least for single instance databases (see ).
Oracle would prefer that we use their Xen-based virtualization platform, but they face an uphill battle to persuade the data centers to move from ESX, which is established as a defacto platform in most sites.
So like it or not, we are probably going to see more databases running on ESX and we’d better understand how to manage ESX virtualized databases. In this post, I’m going to discuss the issues surrounding memory management in ESX.
Configuring memory
When creating a VM in ESX we most significantly configure the amount of “physical” memory provided to the VM. If there is abundant memory on the ESX server then that physical memory setting will be provided directly out of ESX physical memory. However, in almost all ESX servers the sum of virtual memory exceeds the physical ESX memory and so the VM memory configuration cannot be met. The Resources tab options control how VMs will compete for memory.
The key options are:
- Shares. These represent the relative amount of memory allocated to a VM if there is competition. The more shares the relatively larger the memory allocation to the VM. All other things being equal, a VM with twice the number of shares will get twice the memory allocation. However, ESX will “tax” memory shares if the VM has a large amount of idle memory.
- Reservation: This is the minimum amount of physical memory to be allocated to the VM. If there is insufficient memory to honor the reservation then the VM will not start.
- Limit: This is the maximum amount of memory that the VM will use. The advantage of using limit rather than simply reconfiguring the VM memory is that you don’t need to reboot the VM to adjust the memory limit.
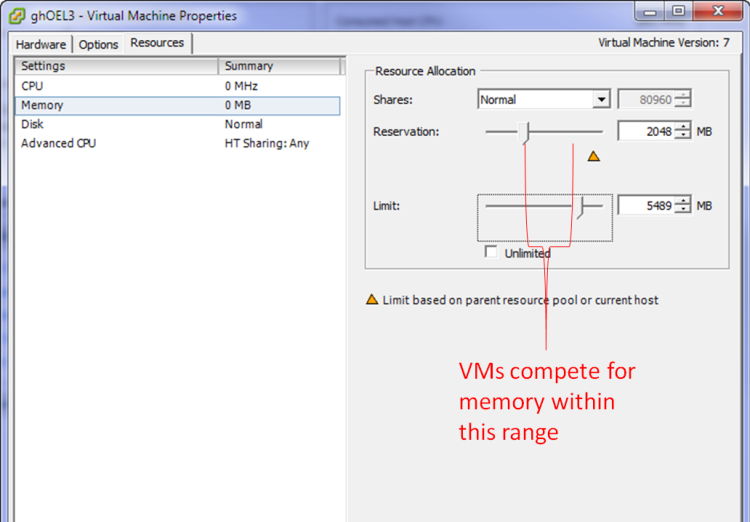
So in general, an ESX VM will have a physical memory allocation between the reservation and the limit. In the event that VMs are competing for memory, the shares setting will determine who gets the most memory.
Ballooning and Swapping
When ESX wants to adjust the amount of physical memory allocated to the VM, it has two options:
- If VMWare tools are installed, ESX can use the vmmemctl driver (AKA the “balloon” driver) which will force the VM to swap out physical memory to the VMs own swapfile.
- If VMWare tools are not installed, then ESX can directly swap memory out to it’s own swapfile. This swapping is “invisible” inside the VM.
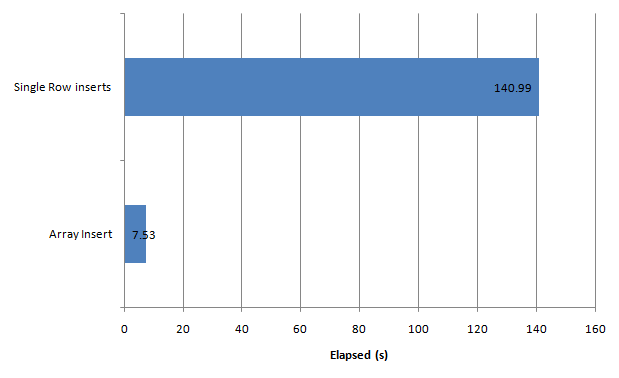
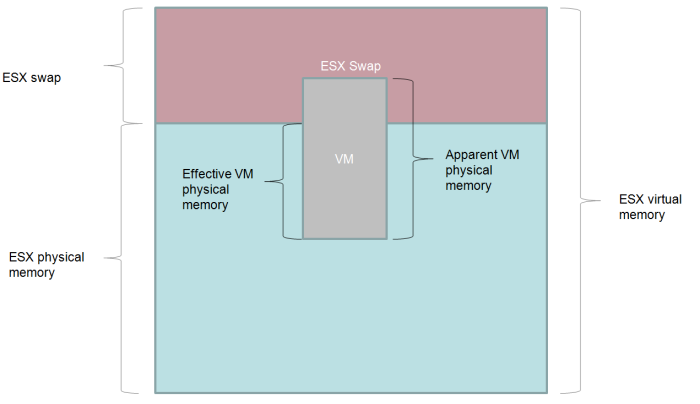
Let’s look at these two mechanisms. Let’s start with a VM which has all it’s memory mapped to ESX physical memory as in the diagram below:
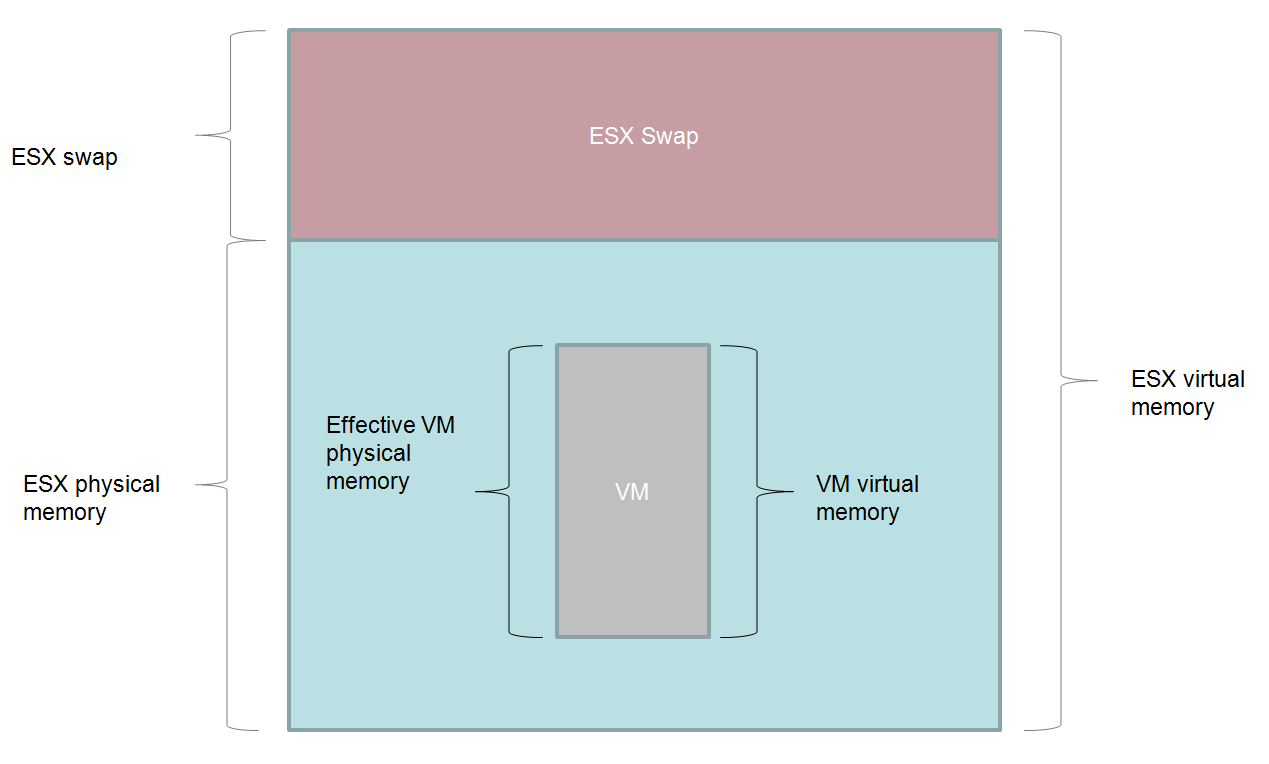
Life is good – VM physical memory is in ESX physical memory, which is generally what we want.
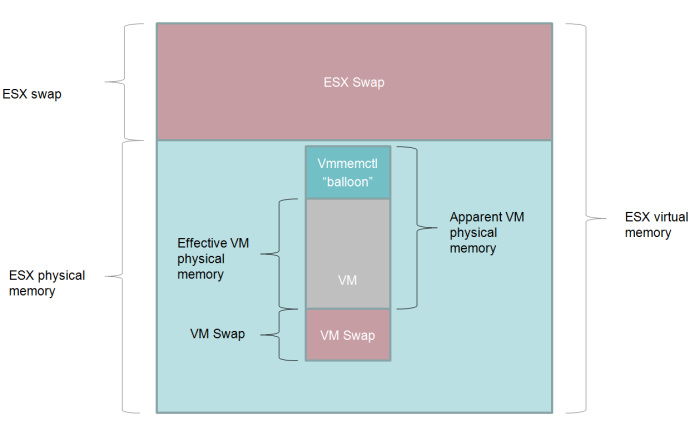
If there is pressure on ESX memory and ESX decides that it wants to reduce the amount of physical memory used by the VM – and VMWare tools is installed – then it will use the vmmemctl driver. This driver is also refered to as the “balloon” driver – you can think of it expanding a balloon within VM memory pushing other memory out to disk. This driver will – from the VMs point of view – allocate enough memory within the VM to force the VM Operating System to swap out existing physical memory to the swapfile. Although the VM still thinks the vmmemctl allocations are part of it’s physical memory address space, in reality memory allocated by the balloon is available to other VMs:
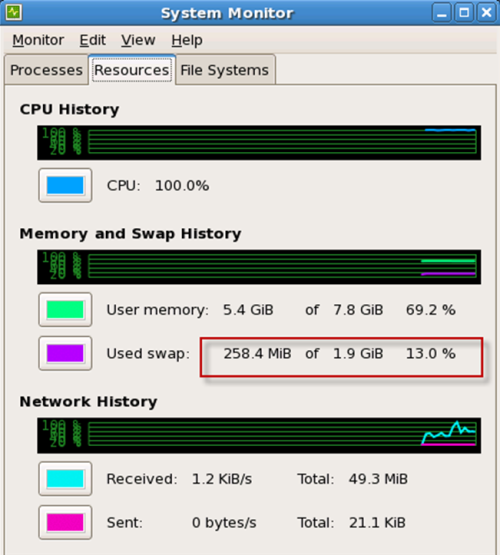
Inside the VM, we can see that memory is swapped out by using any of the standard system monitors:
If VMware tools are not installed, then ESX will need to swap out VM memory to it’s own swap file. Inside the VM it looks like all of the memory is still allocated, but in reality some of the memory is actually in the ESX swap file.
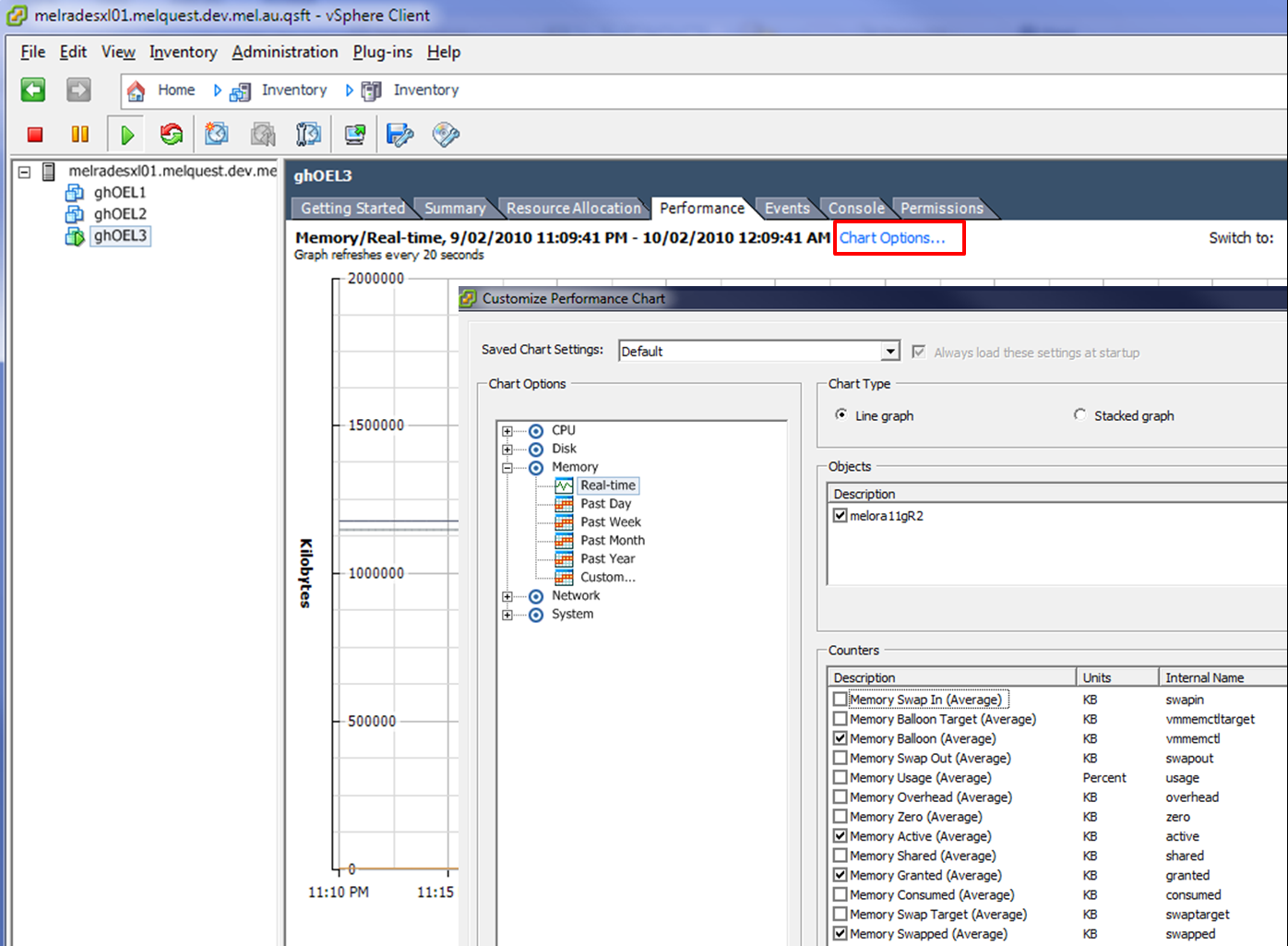
Monitoring memory
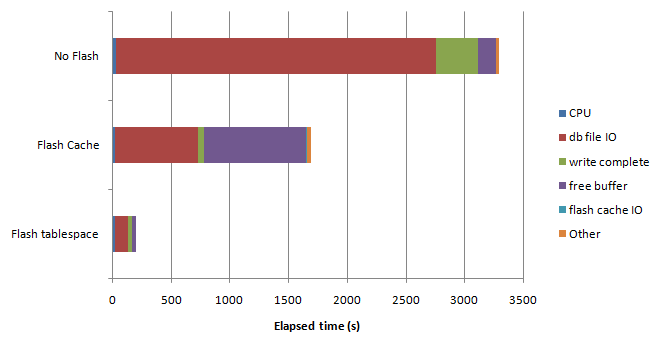
We can see what’s going on in the ESX server by using the Performance monitoring chart. Personally, I like to customize the chart to show just active memory, granted memory, balloon size and swap size as shown below:
Recommendations for Oracle databases
Hopefully we now have some idea how Oracle manages ESX memory and how the physical memory in the VM can be reduced.
Its true that for some types of servers – a mail or file server for instance – having physical memory removed from the VM might be appropriate and cause only minor performance issues. However, for an Oracle database, any reduction in the physical memory of the VM is probably going to result in either SGA or PGA memory being placed on disk. We probably never want that to happen.
Therefore, here are what I believe are the ESX memory best practices for Oracle databases:
- Use memory reservations to avoid swapping. There’s no scenario I can think of in which you want PGA and SGA to end up on disk, so you should therefore set the memory reservation to prevent that from happening.
- Install VMware tools to avoid “invisible” swapping. If VM memory ends up on disk you want to know about it within the VM. The vmmemctl “balloon” driver allows this to occur. Furthermore, the OS in the VM probably has a better idea of what memory should be on disk that ESX. Also, if you use the vmmemctl driver then you can use the LOCK_SGA parameter to prevent the SGA from paging to disk.
- Adjust your Oracle targets and ESX memory reservation together. For instance, if you adjust MEMORY_TARGET in an 11g database, adjust the ESX memory reservation to match. Ideally, the ESX memory reservation should be equal to MEMORY_TARGET plus some additional memory for the OS kernel, OS processes and so on. You’d probably want between 200-500MB for this purpose.
- Don’t be greedy. With physical servers we are motivated to use all the memory we are given. But in a VM environment we should only use the memory we need so that other VMs can get a fair share. Oracle advisories – V$MEMORY_TARGET_ADVICE, V$SGA_TARGET_ADVICE, V$PGA_TARGET_ADVICE – can give you an idea of how performance would change if you reduced – or increased – memory. If these advisories suggest that you can reduce memory without impacting performance then you may wish to do so to make room for other VMs.
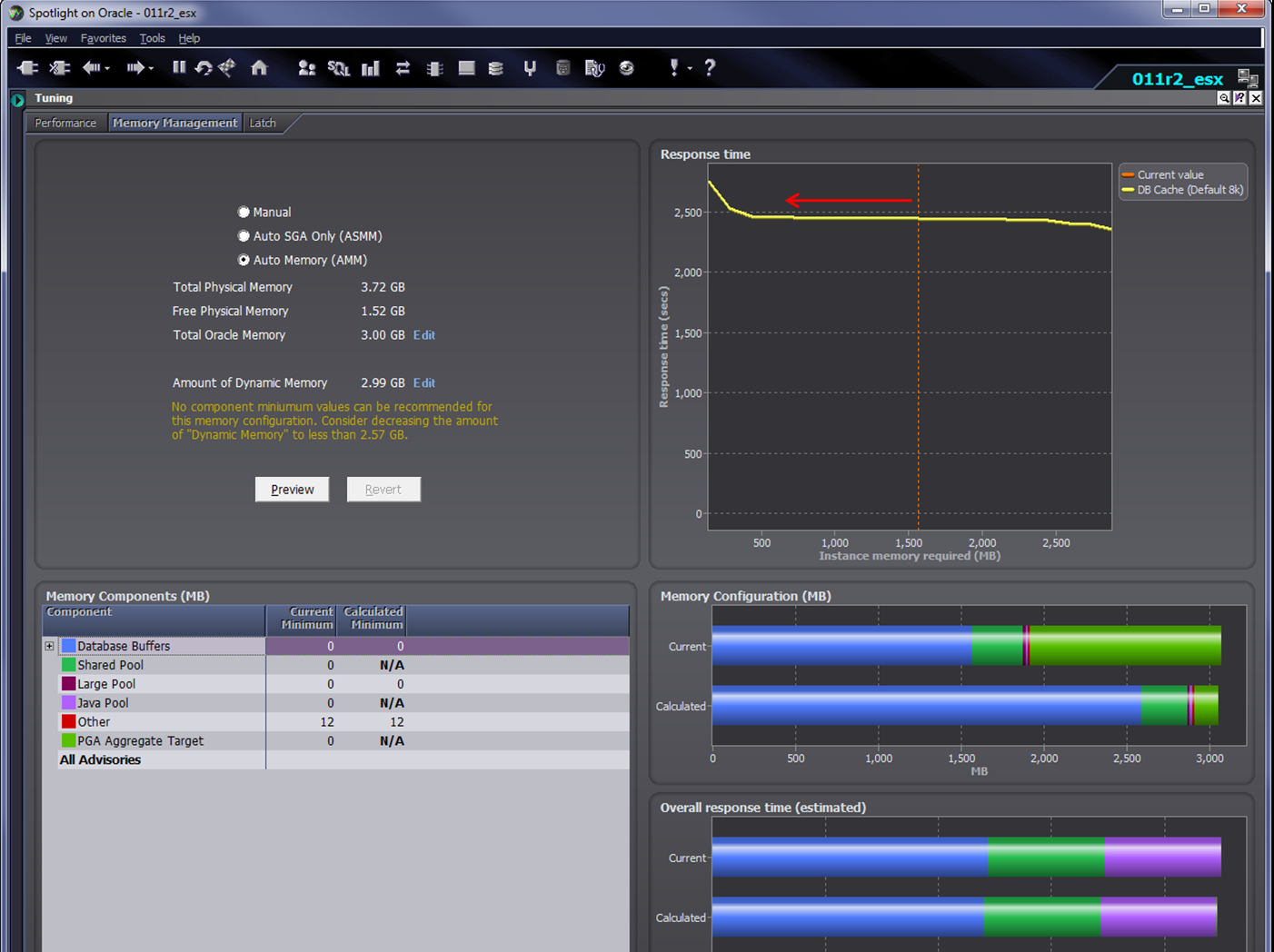
In the next release of Spotlight on Oracle, we will be monitoring ESX swapping and ballooning and raising alarms if it looks like ESX is pushing PGA or SGA out to disk. Spotlight also has a pretty good – if I do say so myself – memory management module that can be used to adjust the database memory to an optimal level (see below). In a future release I hope to enhance that capability to allow you to adjust database and ESX reservations in a single operation.
 Oracle
Oracle