ESX CPU optimization for Oracle Databases
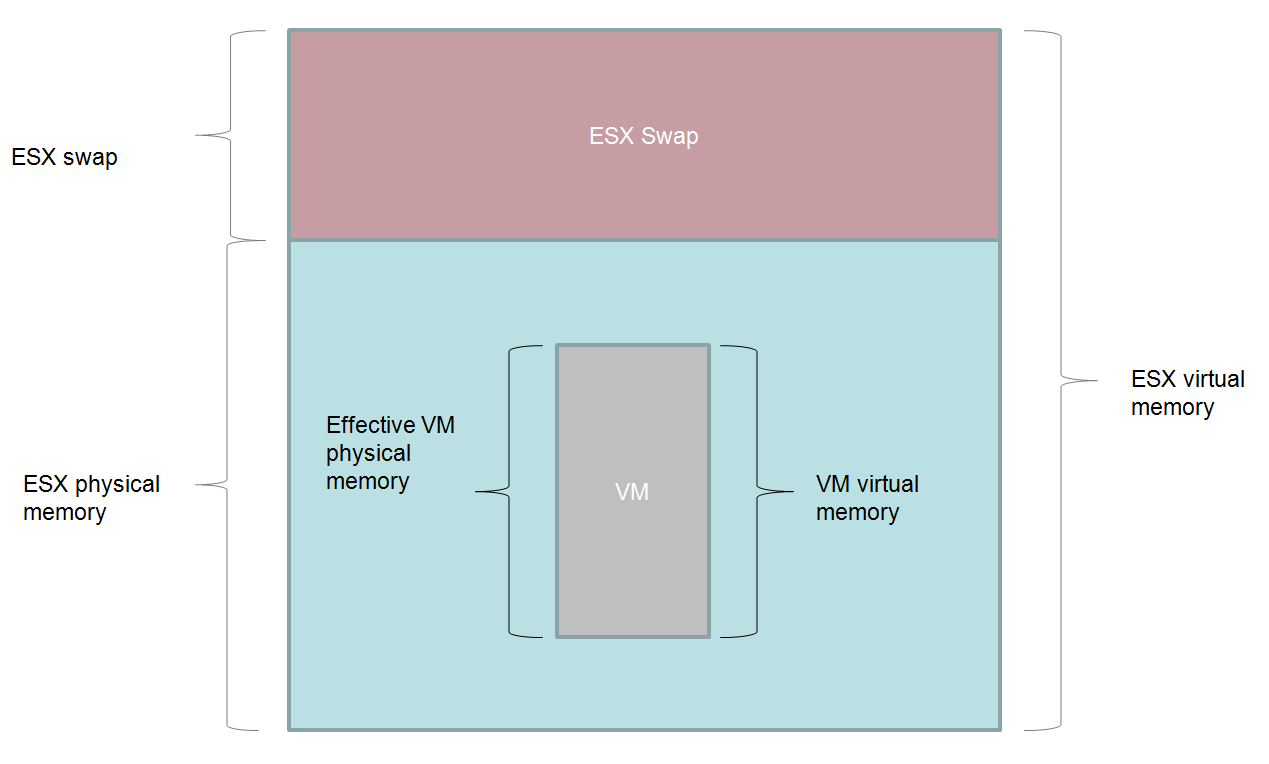
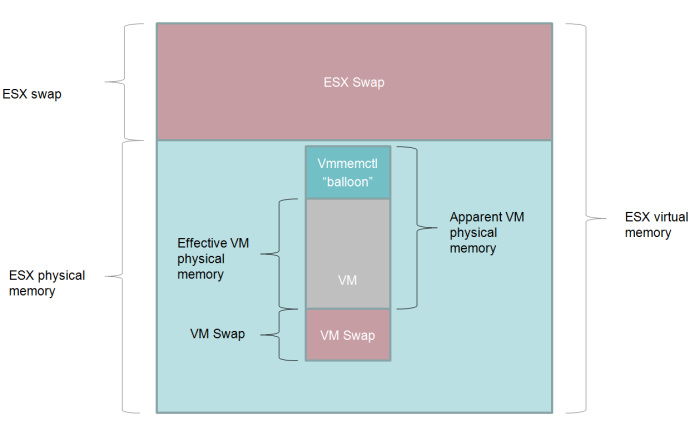
In the last post, I talked about managing memory for Oracle databases when running under ESX. In this post I’ll cover the basics of CPU management.
ESX CPU Scheduling
Everyone probably understands that in a ESX server there are likely to be more virtual CPUs than physical CPUs. For instance, you might have an 8 core ESX server with 16 virtual machines, each of which has a single virtual CPU. Since there are twice as many virtual CPUs as physical CPUs, not all the virtual CPUs can be active at the same time. If they all try to gain CPU simultaneously, then some of them will have to wait.
In essence, a virtual CPU (vCPU) can be in one of three states:
- Associated with an ESX CPU but idle
- Associated with an ESX CPU and executing instructions
- Waiting for an ESX CPU to become available
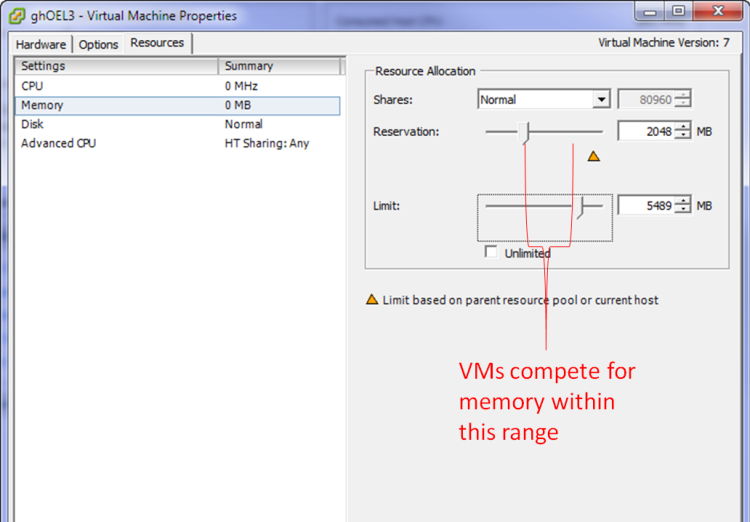
As with memory, ESX uses reservations, shares and limits to determine which virtual CPUs get to use the physical CPUs if the total virtual demand exceeds physical capacity.
- Shares represent the relative amount of CPU allocated to a VM if there is competition. The more shares the relatively larger number of CPU cycles will be allocated to the VM. All other things being equal, a VM with twice the number of shares will get access to twice as much CPU capacity.
- The Reservation determines the minimum amount of CPU cycles allocated to the VM
- The Limit determines the maximum amount of CPU that can be made available to the VM
VMs compete for CPU cycles between the limit and their reservation. The outcome of the competition is determined by the relative number of shares allocated to each VM.

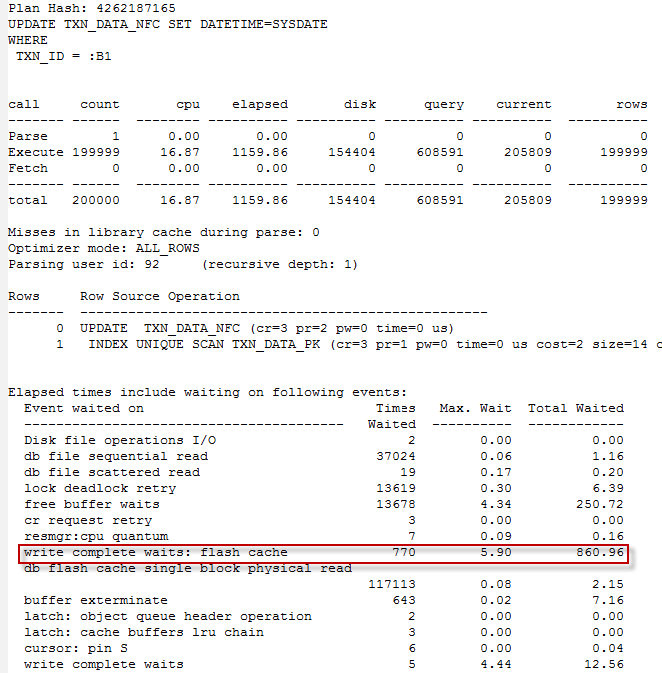
Measuring CPU consumption in a virtual machine
Because ESX can vary the amount of CPU actually allocated to a VM, operating system reports of CPU consumption can be misleading. On a physical machine with a single 2 GHz CPU, 50% utilization clearly means 1GHz of CPU consumed. But on a VM, 50% might mean 50% of the reservation, the limit, or anything in between. So interpreting CPU consumption requires the ESX perspective as to how much CPU was actually provided to the VM.
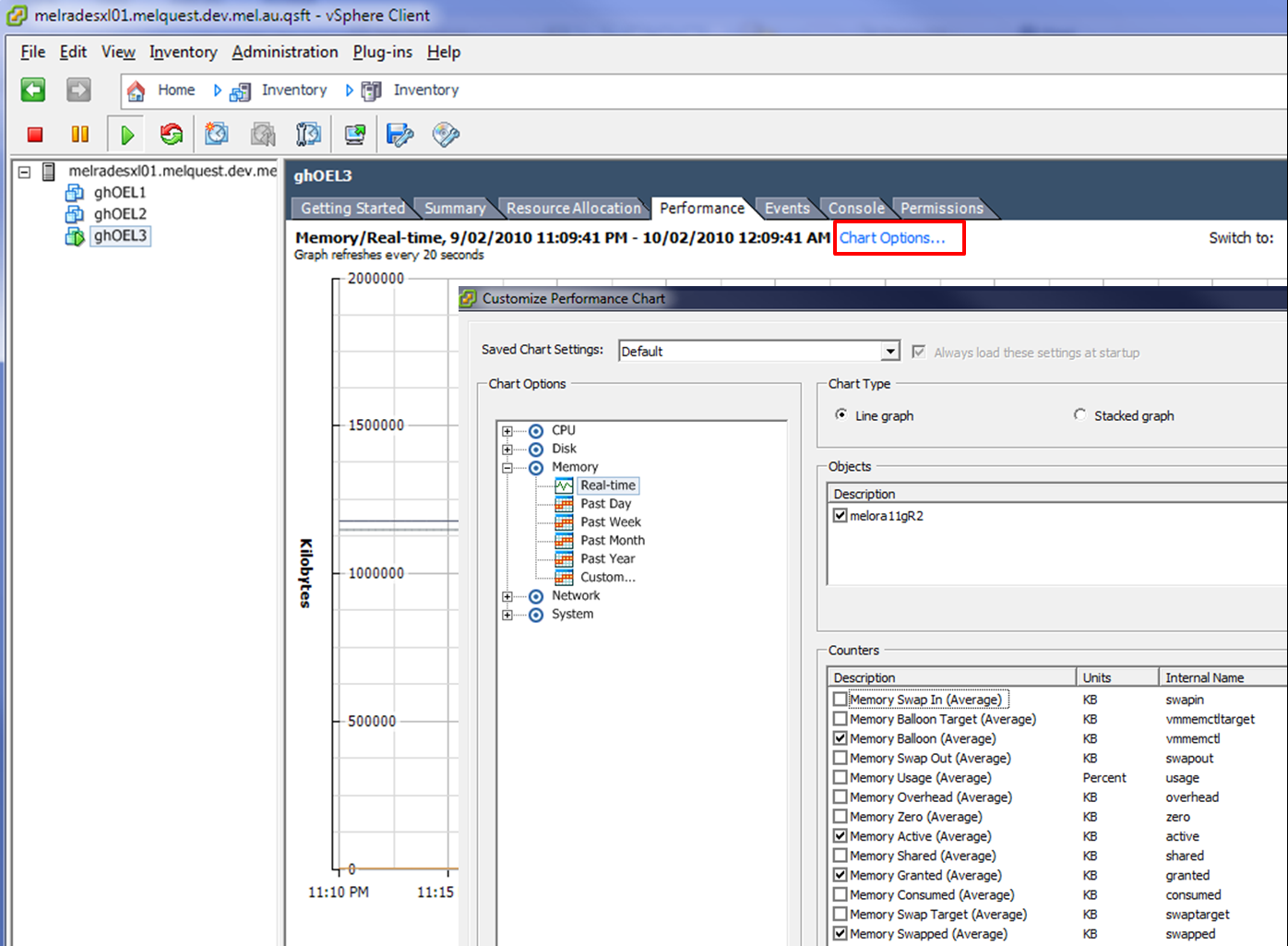
The Performance monitor in the vSphere client gives us the traditional measures of CPU consumption: CPU used, CPU idle, etc. However it adds the critical “CPU Ready” statistic. This statistic reflects the amount of time the VM wanted to consume CPU, but was waiting for a physical CPU to become available. It is the most significant measure of contention between VMs for CPU power.
For instance in the chart below, we can see at times that the amount of ready time is sometimes almost as great as the amount of CPU actually consumed. In fact you can probably see that as the ready time goes up, the VMs actual CPU used goes down – the VM wants to do more computation, but is unable to do so due to competition with other VMs.

The display of milliseconds in each mode makes it hard to work out exactly what is going on. In the next release of Spotlight on Oracle (part of the Toad DBA suite) we’ll be showing the amount of ready time as a proportion of the maximum possible CPU, and provide drilldowns that show CPU limits, reservations, utilization and ready time.
Co-scheduling
For a VM with multiple virtual CPUs, ESX needs to synchronize vCPUs cycles with physical CPU consumption. Significant disparities between the amounts of CPU given to each vCPU in a multi-CPU VM will cause significant performance issues and maybe even instability. A “strict co-scheduling policy” is one in which all the vCPUs are allocated to the physical CPUs simultaneously, or at least when any one CPU falls significantly behind in processing. Modern ESX uses “relaxed co-scheduling” in which only CPUs that have fallen behind need to be scheduled.
In practice however, on a multi-CPU system all the CPUs generally consume roughly equivalent amounts of CPU and most of the time all of them will need to be scheduled together. This can make it harder for ESX to allocate CPUs. For instance, in the diagram below we see how the more vCPUs are configured, the fewer scheduling choices are available to the ESX scheduler:

(Thanks to Carl Bradshaw for letting me reprint that diagram from his Oracle on VMWare whitepaper)
As a result, you can actually find performance decreasing as the number of cores increases. This will be most apparent if you try and configure as many vCPUs as physical CPUs.
Even if there is no competition from other virtual machines, the ESX hypervisor itself will require CPU resources and find it difficult to schedule all the cores of the VM. This is very noticeable on VMware workstation: if you create a two-CPU virtual machine on a dual core laptop, it will almost certainly perform worse than a single CPU VM, because VMware will have trouble scheduling both the vCPUs simultaneously.
In general, don’t allocate a lot of vCPUs unless you are sure that the ESX server is usually under light load from other VMs and that your database actually needs the extra cores.
Summary
Effective ESX memory configuration requires co-ordination between Oracle’s memory management and the ESX memory management to avoid PGA or SGA ending up on disk. CPU is a lot simpler. In general I recommend the following:
- Avoid over-allocating CPU cores: don’t automatically assume that more CPUs will lead to better performance
- Use reservations, limits and shares to determine the relative amount of CPU that will be allocated to your VM
- Monitor the ESX “CPU ready” statistic to determine how competition with other VMs is affecting your virtualized databases’ access to CPU.
 Oracle
Oracle